
Introduction
We have got in excess of 300 TB of essential unknown data. At the State and University Library in Denmark we recently passed 300TB of harvested web resources in our web archive. These web resources have been harvested by crawling the Danish part of the internet since 2005, i.e. from every publicly available URL on the Danish top level domain “.dk”. This harvesting is done in a couple of different ways. We have scheduled crawls four times a year that do a complete harvest of the whole of .dk. We also harvest selected sites on e.g. an hourly schedule at big national events like elections for the government or royal weddings.
Due to privacy and copyright concerns these harvested web resources are stored in a so-called “dark archive” with means that basically these resources are inaccessible for anyone but the most serious researchers. Still, we are obliged to ensure these web resources remain accessible and in order to do so it is imperative that we know the content of our archive. Such knowledge is generally expressed through format identifiers such as MIME types and PRONOM IDs.
During the harvest we also collect available metadata from the web servers, e.g. the MIME type of the documents. This MIME type is deduced by the web server from simple attributes like document extension and it is therefore considered unreliable. We recently did a very informal check on that assumption. We ran the Apache Tika tool on a few thousand web resources and compared the extracted MIME type with that of the web server. We found that for most of the web resources the two MIME types actually matched. Surprising? Still, knowing what we have got does not limit itself to identification by its MIME type. We also need to acquire information on document version, image types, sizes, bit rates etc. Values that are not served by the web server during the harvesting.
To acquire such data one has a wide range of tools to select from. The SCAPE report Characterisation technology Release 1 — release report outlines some of these tools and their pros and cons.
Running FITS
As part of the SCAPE project we were asked by the Planning and Watch sub project to produce input data for an experimental project they worked on, a project which later became C3PO. C3PO is a tool used for repository profiling based on characterisation data from the repository. Planning and Watch asked us to use FITS on a selected part of our web archive to produce such characterisation data. The arguments behind this choice of FITS can is detailed in the article To FITS or not to FITS. To comply we selected representative parts of our web archive for each year we have harvested data.
Our web archive data is stored in ARC files. An ARC file contains a arbitrary number records, each record consisting of a header followed by the raw web resource.
The representative corpus is described in numbers in the following table
| Year of harvest | Number of ARC files |
|---|---|
| 2005 | 4024 |
| 2006 | 20497 |
| 2007 | 17139 |
| 2008 | 30685 |
| 2009 | 23019 |
| 2010 | 14090 |
| 2011 | 13386 |
We started this job in November 2011 and as of November 2012, when the analysis described here-in was performed, the job had processed more than 100000 ARC files amounting to almost 12TB or just above 400 million web resources.
The platform on which we were able to execute the job consisted of five Blade servers (Intel® Xeon® Processor X5670), each with twelve cores and a total memory of 288GB. The servers are connected to a SAN through 1GB ethernet. To handle the distribution and load balancing for the job we wrote a simple system in Bash. The code for this system is published as SB-Fits-webarchive on Github. Keep in mind that this system was created solely for this specific experimental data gathering task.
One thing we noticed when gathering data for this analysis is that FITS completely lacks any performance metrics. From the FITS data itself we cannot know anything about how long each ARC file took to process etc. Initially, we also did not record the numerous times we had to restart a FITS process either due to a crash or some infinite loop. When running the job, this was never a concern to us as the intention of this experiment solely was to produce FITS metadata as input to the C3PO project.
Fortunately, this does not mean that we are completely without performance metadata. Examining the result files we can deduce some information on the performance.
The Result files
An ARC file contains a certain number of records where each record is a web resource. Such a resource can have a format like HTML, XHTML, XML, PDF, Flash, DOC, mp3, GIF, MPG, EXE, etc. For each record FITS produces an XML file including all the characterisation information extracted by all the modules FITS is configured to run on a given format. The produced XML files from a single ARC file are after the FITS run packed into a tarball for later processing.
Getting the performance data
Timing from the TGZ files
To get the timing metrics of the FITS jobs we look at the modification time of the individual XML files within the tarball of FITS results corresponding to a given ARC file. This has some implications, e.g. we are not able to get timing information for the first XML file or for ARC files containing a single record. Still, given the amount of data created by the FITS experiment, this should not give rise to any significant problem.
The source code for this timing extraction tool can be found at the fits-analysis Github page.
ARC file sizes
An ARC file consists of any number of records. The harvesting system is configured to produce ARC files with a size of 100MB, but, as will be seen in the following, not all files adhere to this limitation. Therefore we would like to use the precise size in the analysis and need to obtain these sizes from the original ARC files.
As the cluster we used for the experiment does not have local storage we had to apply a rather cumbersome process of transferring the ARC files from the production storage system to a work area, both storage systems are located on a SAN. After copying an ARC file to the work area it was unpacked for FITS to run on each unpacked record. Lastly, the ARC file and all its records were deleted before fetching the next ARC file.
To obtain the ARC file sizes for this analysis we used the original configuration file listing the data corpus and then had a Bash job use 'ls' over ssh to the production storage for each ARC file that had been characterised. Fortunately, this only took a few days to complete.
Analysis
After the above data extractions we have the following data set.
| parameter name | description |
|---|---|
| ARC file name | this name could be used for further data acquisition |
| count | the number of records |
| length | the size of the FITS results file. This is not used. |
| time | the time it took in seconds to process the ARC file.** |
| size | the size of the ARC file in MB |
** As mentioned above, the processing time is calculated as the difference in modification time from the oldest and the youngest XML file in the tarball.
Every ARC file contains an arbitrary number of records that each has an arbitrary size and type. Therefore we do not expect any correlation between the ARC file size and the number of records in a given ARC file nor the time it took to process each file. Still, scatter plots might show some interesting artefacts.
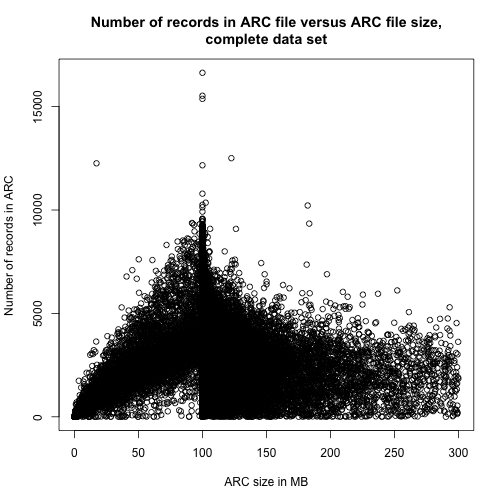
Looking closely at the region below the 100MB limit gives us a fine linear correlation but one might wonder why we see such a big difference below and above the 100MB peak.
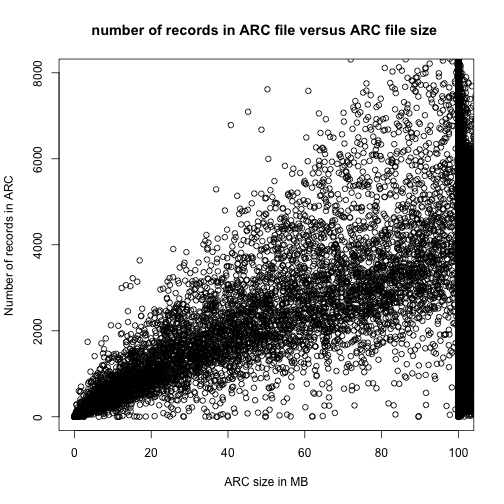
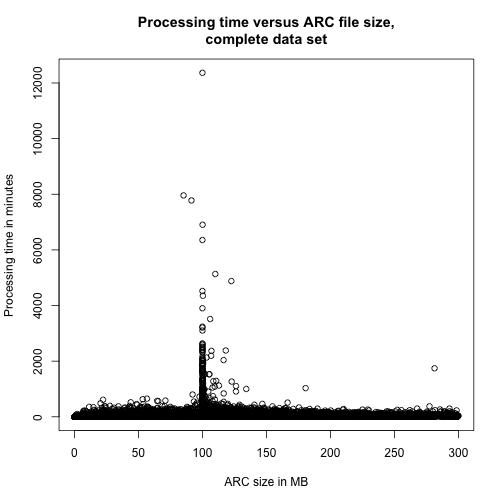
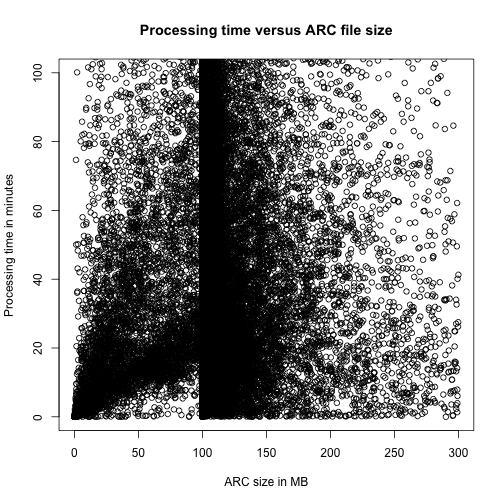
Another way of looking at the data would be simple histograms like the following three charts
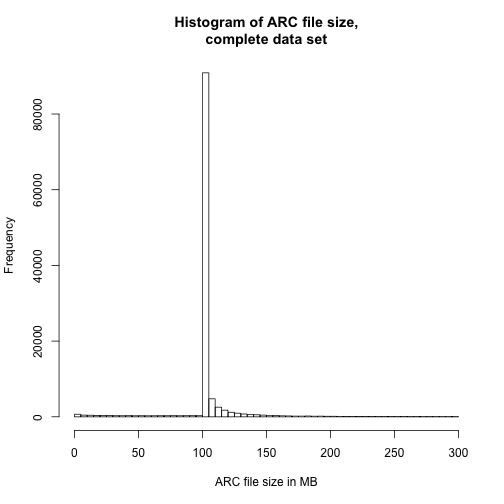
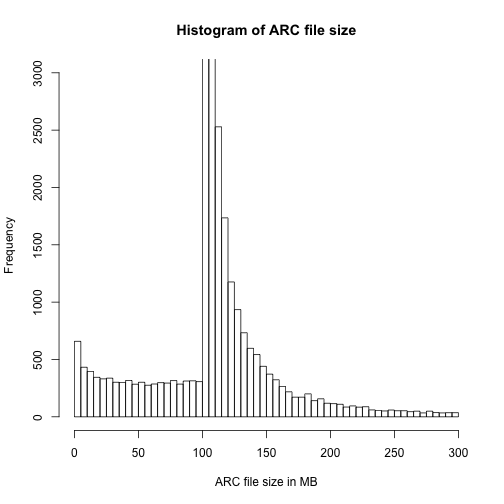
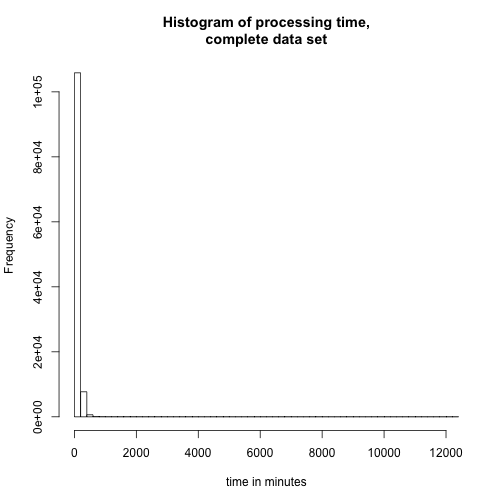
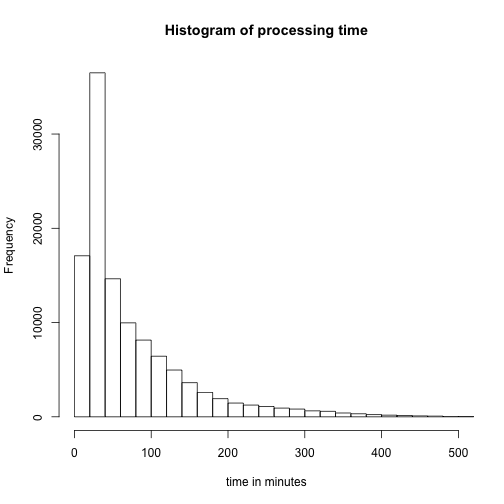
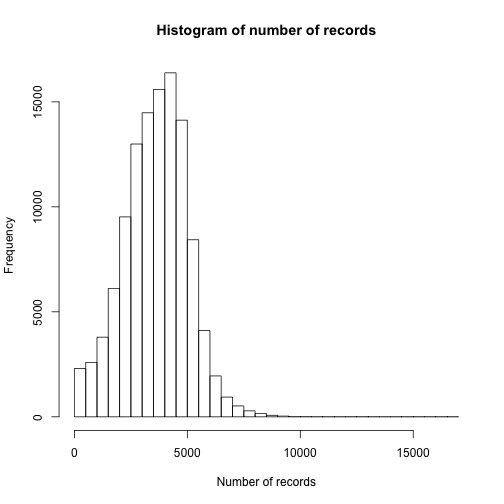
In all of the data visualisations above, it is evident that we are dealing with a lot of outliers and very long tails. As this is just a preliminary examination of the performance of FITS, we will choose to ignore some of these features.
The hard peak at around 100MB in ARC file size arises from a configuration of the harvest process. 87.3978% of the files lies in the interval from 99MB to 120MB.
The hard peak in the processing time histogram probably stems from problems in the FITS program. Furthermore, it might be affected by our load balancing system. If we choose to ignore this long tail, i.e. only look at data samples with a processing time below 8000 seconds, we reduce the corpora to 84.1339% of the original corpora.
If we reduce the corpora by both rules above, we get a corpora the size of 72.3009% which for this purpose is enough.
A deeper investigation of the long tail might reveal some of the bottlenecks of FITS combined with our load balancing system. That investigation will not be accounted for here.
We can now calculate the processing speed which has the following distribution
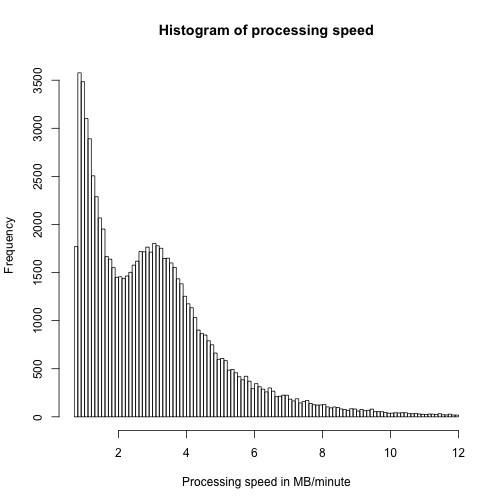
The processing speed is distributed from 0.75 MB/minute to 6000 MB/minute, but the tail already begins below 10 MB/minute. Again, closer examination of this very long tail, which could be done by e.g. including MIME types, might reveal some of the problems with FITS.
Another apparent feature in this visualisation is the two distinct maxima. What features in ARC files can give rise to such a phenomena?
A few statistical numbers from this speed data sample
| parameter | value |
|---|---|
| 1st quartile | 1.448 MB/minute |
| median | 2.738 MB/minute |
| mean | 3.951 MB/minute |
| 3rd quartile | 4.024 MB/minute |
So, using the above corpora reductions we get a median for the speed at 2.7 MB/minute, but it is important to note that the corpora exhibits very long tails and outliers in all parameters. One should therefore be very careful before drawing any generalised conclusions.
Wall time
As I stated in the introduction, we have been running this FITS job for a year to gather this data. If we take the 11.64TB of ARC files and divide that amount by by a year we get a processing speed of 30 MB/minute. The median speed calculated in the previous section is for a single process. This would seem to state that we have got a circa 10 time speed increase running on a cluster of up to four processes on five 12 core servers, which sounds reasonable considering the instability of FITS.
Conclusion and what's next
Before concluding anything about this experiment and analysis, a comment on the FITS tool versus our corpora is due. We have employed FITS on perhaps the most difficult corpora there is. 12TB of random, unknown and very heterogeneous data spanning most known digital formats—at least known in Denmark. The critique of FITS is only related to how it performs on such a corpora. FITS do have lots of qualities, most importantly it aggregates characterisation data from a whole range of tools into a common format. That being said, if we were to use the presently available FITS tool to characterise our web archive, it would take us 300 TB divided by 10 TB per year per five servers. I.e. on the present cluster the job wouldn't finish until after we all were retired.
We have stated in the first SCAPE evaluation that we want to be able to characterise a harvest of the complete Danish Internet in weeks, preferable less than three weeks. Such a harvest amounts to around 25TB and would thus take us two and a half years with the present set-up. In other words, we would need to acquire a cluster the size of 40 times what we have used for this experimental FITS job. That is probably not going to happen! So if we want to do this kind of characterisation we need to improve on the software and the general platform while, of course, still looking into up-sizing our hardware within the economically possible.
In short, the FITS tool as it is now is not fast enough for real world web archives. On the other hand we think that the data presented here might be of help in optimising both the FITS tool and how we use it. As we know the MIME type of each and every data point, a deeper investigation of the outliers and the long tails might reveal the bottlenecks of this setup and maybe even where to avoid using FITS or specific FITS modules. During the job we have also been gathering lists of files which caused FITS to crash. In other words a lot of data that could be used for bug reporting—–and fixing. So this blog post is not only presenting the data from an experiment, but just as important we want to share code, data, and ideas for digital preservation.
The job is still running and it is now characterising web resources for 2012 so the story will be continued…


January 31, 2013 @ 1:59 pm CET
Good to know that we individual threads for each tool. Thanks for looking into this!
We will definitely use the Java API if possible, but the above presented experiment ran outside a Java environment. Still, we're always looking for ways to improve our possibilities with these characterisation tools.
January 29, 2013 @ 2:32 pm CET
Looking back at the release notes (https://code.google.com/p/fits/source/browse/trunk/RELEASE.txt) FITS 0.6.0 does spin up each tool in an individual thread by default. When I first implemented this I remember benchmarking a 20-30% increase in performance.
Using the Java API should be more efficient than calling FITS from the command line tool for every file. I haven't measured it, but initialization overhead should be reduced. The Java API also gives you control over enabling and disabling individual tools if you know they are not needed. You can also do this by commenting them out from the xml/fits.xml (https://code.google.com/p/fits/source/browse/trunk/xml/fits.xml) configuration file.
January 16, 2013 @ 7:42 am CET
The actual FITS jobs are distributed on five servers and each server run four parallel instances of FITS, i.e. we should at any given time have 20 ARC files being processed simultaneous. Using UNIX top we can see that each of these FITS instances have a load above 100%. Still, we might start experimenting with running even more parallel FITS instanses on each server.
We are using FITS version 0.6.0 and it’s run with its default configuration. Therefore I assume that we don’t run the various tools of FITS in seperate threads. Still, why would that feature not be part of the default?
We haven’t looked at Open FITS.
AS I wrote in the post, there’s a lot of room for improvement, BUT there’s also a very very long way before we have the nessecary performance.
January 14, 2013 @ 3:06 pm CET
Very interesting posting on an important issue.
I was wondering if you could provide some more information around the use of multi threading.
The latest version of FITS allows the various tools to be run in seperate threads. Are you making use of this in your study?
Also have you or are you able to run multiple instances of FITS itself, hence process multiple ARC files simultaneously?
Thanks for any information you can provide.