
Statsbiblioteket (The State and University Library, Aarhus, hereafter called SB) welcomed a group of people from The Royal Library, The National Archives, and Danish e-Infrastructure Cooperation on June 25, 2014. They were invited for our SCAPE Demo day where some of SCAPE’s results and tools were presented. Bjarne S. Andersen, Head of IT Technologies, welcomed everybody and then our IT developers presented and demonstrated SB’s SCAPE work.
The day started with a nice introduction to the SCAPE project by Per Møldrup-Dalum, including short presentations of some of the tools which would not be presented in a demo. Among others this triggered questions about how to log in to Plato – a Preservation Planning Tool developed in SCAPE.
Per continued with a presentation about Hadoop and its applications. Hadoop is a large and complex technology, which was already decided to use before the project started. This has resulted in some discussion during the project, but Hadoop has proven really useful for large-scale digital preservation. Hadoop is available both as open source and as commercial distributions. The core concept of Hadoop is the MapReduce algorithm which was presented in the paper “MapReduce: Simplified Data Processing on Large Clusters” in 2004 by Jeffrey Dean and Senjay Ghemawat. This paper prompted Cutting and Cafarella to implement Hadoop and they published their system under an open source license. Writing jobs for Hadoop has traditionally been done by using the Java programming language, but in the recent years several alternatives to Java have been introduced, e.g. Pig Latin and Hive Other interesting elements in a Hadoop cluster are HBase, Mahout, Giraph, Zookeeper and a lot more. At SB we use an Isilon Scale-Out NAS storage cluster which enables us to make a lot of different experiments on the four 96GB RAM CPU nodes each with a 2 Gbit Ethernet interface. This setup potentially makes the complete online storage of SB reachable for the Hadoop cluster.

Bolette A. Jurik was next in line and told the story about how Statsbiblioteket wanted to migrate audio files using Hadoop (and Taverna…. and xcorrSound Waveform Compare). The files were supposed to be migrated from mp3 to wav. Checking this collection in Plato gave us the result ‘Do nothing’ – meaning leave the files as mp3. But we still wanted to perform the experiment – to test that we have the tools to migrate, extract and compare properties, validate the file format and compare the content of the mp3 and wav files, and that we can create a scalable workflow for this.". We did not have a tool for the content comparison, so we had to develop one, xcorrSound waveform-compare. The output shows which files need special attention – as an example one of the files failed the waveform comparison although it looked right. This was due to a lack of content in some parts of the file so Waveform Compare had no sound to compare! Bolette also asked her colleagues to create "migrated" soundfiles with problems that the tool would not find – read more about this small competition in this blog post.
Then Per was up for yet another presentation – this time describing the experiment: Identification and feature extraction of web archive data based on Nanite. The test was to extract different kinds of metadata (like authors, GPS coordinates for photographs etc.) using Apache Tika, DROID, (and libmagic) . The experiment was run on the Danish Netarchive (archiving of the Danish web – a task undertaken by The Royal Library and SB together). For the live demo a small job with only three ARC files was used – taking all of the 80,000 files in the original experiment would have lasted 30 hours. Hadoop generates loads of technical metadata that enables us to analyse such jobs in detail after the execution. Per’s presentation was basically a quick review of what is described in the blog post A Weekend With Nanite.
An analysis of the original Nanite experiment was done live in Mathematica presenting a lot of fun facts and interesting artefacts. For one thing we counted the number of unique MIME types in the 80,000 ARC files or 260,603,467 individual documents to
- 1384 different MIME types were reported by the HTTP server at harvest time,
- DROID counted 319 MIME types,
- Tika counted 342 MIME types.
A really weird artefact was that approx. 8% of the identification tasks were complete before they started! The only conclusion to this is that we’re experiencing some kind of temporal shift that would also explain the great performance of our cluster…
Two years ago SB concluded a job that had run for 15 months. 15 months of FITS characterising 12TB of web archive data. The experiment with Nanite characterised 8TB in 30 hours. Overall this extreme shift in performance is due to our involvement in the SCAPE project.
After sandwiches and a quick tour to the library tower Asger Askov Blekinge took over to talk about Integrating the Fedora based DOMS repository with Hadoop. He described Bitmagasinet (SB’s data repository) and DOMS (SB’s Digital Object Management System based on Fedora) and how our repository is integrated with Hadoop.
SB is right now working on a very large project to digitize 32 million pages of newspapers. The digitized files are delivered in batches and we run Hadoop map/reduce jobs on each batch to do quality assurance. An example is to run Jpylyzer on a batch (Map runs Jpylyzer on each file, Reduce stores the results back in DOMS). The SCAPE way to do it includes three steps:
- Staging – retrieves records
- Hadooping – reads, works and writes new updated records
- Loading – stores updated records in DOMS
The SCAPE Data model is mapped with the newspapers in the following way:
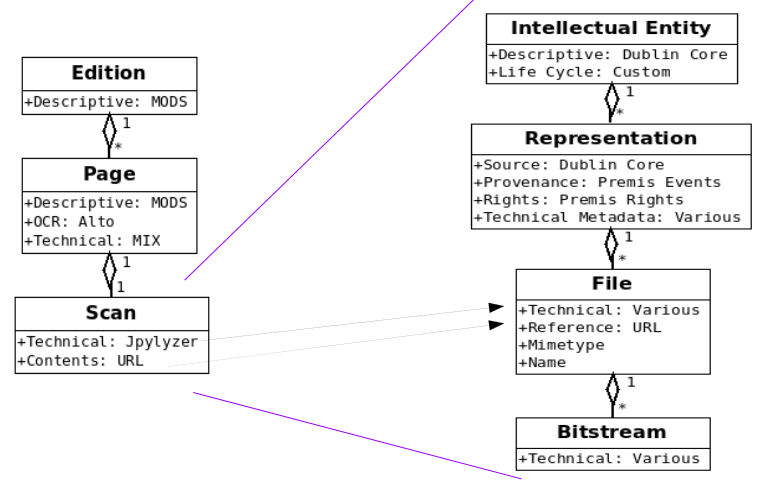
SCAPE Stager/Loader creates a sequence file which can then be read and each record updated by Hadoop and after that the records are stored in DOMS.
The last demo was presented by Rune Bruun Ferneke-Nielsen. He described the policy driven validation of JPEG 2000 files based on Jpylyzer and performed on SB’s Newspaper digitization project. The newspapers are scanned from microfilms by a company called Ninestars, and then quality assured by SB’s own IT department. We need to make sure that the content conforms to the corresponding file format specifications and that the file format profile conforms to our institutional policies.
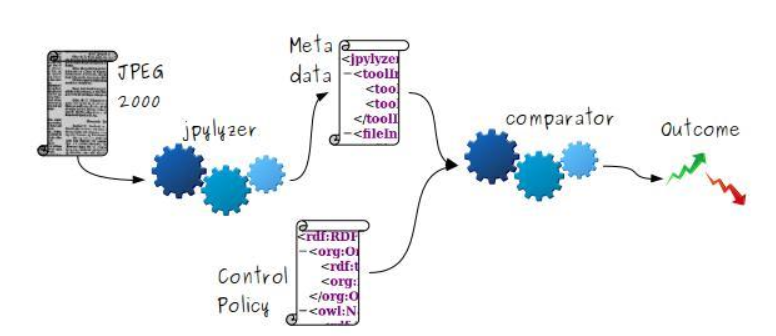
530,000 image files have been processed within approx. five hours.
We want to be able to receive 50,000 newspaper files per day and this is more than one server can handle. All access on data for quality assurance etc. is done via Hadoop. Ninestars runs a quality assurance before they send the files back to SB and then the files are QA’ed again inhouse.

One of the visitors at the demo is working at The Royal Library with the NetArchive and would like to make some crawl log analyses. These could perhaps be processed by using Hadoop – this is definitely worth discussing after today to see if our two libraries can work together on this.
All in all this was a very good day, and the audience learned a lot about SCAPE and the benefits of the different workflows and tools. We hope they will return for further discussion on how they can best use SCAPE products at their own institutions.


