

Note: This post includes hexadecimal numbering to represent byte values. Where appropriate hex values are preceded with ‘0x’, e.g. 0xA1B2.
Last week was notably busy from a PRONOM contribution perspective so I thought I would share some words about the work, in the spirit of Ross Spencer’s five principles for better information sharing for file format signature development. You can view previous posts on PRONOM here.
The nature of this work is somewhat technical so you may wish to review The National Archives’ technical guidance on Developing File Format Signatures if you are interested in exploring the concepts discussed here in more detail.
The week began with replying to a query from Jenny Mitcham of The Borthwick Institute for Archives. Jenny has been participating in ‘Filling the Digital Preservation Gap’ – a collaborative project between the Universities of Hull and York looking at the challenges of preserving research data file formats.
Jenny has blogged about her research already. She settled on researching the .spa files in her collection and found them to be Spectral Data Files. From Jenny’s sample set, she had observed a common byte sequence at the beginning of each file: Hex values 0x537065637472616C20446174612046696C650D0A00000000000000000000

I had suggested shortening the signature to just 0x537065637472616C20446174612046696C65, eliminating the 0x0D0A part and the long sequence of zeroes. Jenny was curious as to why and whether it was good practice to get rid of these ‘dot’ values from signatures generally.
Best practice is to measure the file format specification against what is being observed and to rely on sequences that are defined as being fixed and constant, however in the absence of the file format specification we have to rely on observation and interpret what we can.
In my hex editor, each ‘dot’ with the exception of hex value 0x2E which is a full stop (not present in this image), represents a byte from the ASCII non-text range – less than hex value 0x20.
Byte values in this range 00-1F can have different meanings, for example some file formats declare their version numbers using byte values, so 0x01 = version 1, 0x0A = version 10, etc.
However, ASCII was originally designed for teletype terminals, and the bytes 00-1F have special meaning to the interpreter and this is still the case in today’s virtual terminal environments. 0x0D0A is a very common combination to see when examining file formats and it interprets as ‘carriage return (0D), line feed (0A)’ – basically this combination is typically written out (or more accurately, sent to the terminal) when you hit enter on your keyboard. Byte 00 is ‘null’, meaning “there is a byte here, but it has no value.” You can see what these special characters mean on an ASCII character table.
Many specifications allow reserved space for descriptive text of variable length, with unused bytes left as null. To give a simple example, a specification might declare the following:
CHAR[8] # title, unused CHARs null
Meaning, an 8 character space for a title, with unused characters set to null.
So the following text would be interpreted with the following hex:
‘Allspace’ – hex 0x416C6C7370616365
‘Half’ – hex 0x48616C6600000000
[empty] – hex 0x0000000000000000
So in the .spa files, because we don’t have a specification, we don’t know exactly what those null bytes represent. Although we’ve witnessed those null bytes in all of the sample files, we can’t be sure they’re always going to be there or if they might have a different value in specific circumstances, so in this case it’s prudent to drop them from the proposed signature.
Meanwhile the text string at the very beginning of the file is very specific, so it’s unlikely to clash with any other file format and is therefore strong enough to rely on for identification for now, with the potential to improve the identification signature should our understanding of the format improve.
Next, Jenn Morris of MIT Libraries raised an issue on the DROID GitHub page regarding unidentified WAV audio files of 6GB in size, asking if there was a limit to the file size that DROID could handle. DROID shouldn’t have issues with files of this size, so I wondered if it might be a PRONOM signature issue.
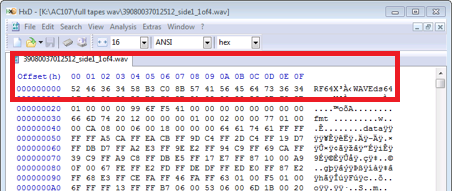
I asked Jenn to provide a screen grab of the beginning of the file within a hex editor, and I had understood WAV to have a size limit of 4GB (due to a hard limit for 32 bit addressing), so thought it would turn out to be a slightly different file type. We had previously added a PRONOM entry in collaboration with National Library of New Zealand for the ‘RF64’ audio format – a 64 bit extension to WAV allowing a theoretical file size limit of around 16 exabytes (16 billion GB). I thought it might be a similar type, and so in lieu of the screen grab I started looking at other 64 bit WAV-like audio formats.
I found a reference to a Sonic Foundry WAVE 64 or Sony Media WAVE 64 format on the WAV Wikipedia entry and I was able to generate samples with the Audacity audio tool and subsequently determine a potential identification signature. As often happens I fell down a rabbit hole of researching audio formats that are yet to be in PRONOM and I should be able to add at least a further eight audio formats in the next PRONOM release as a result.
Jenn replied with a screen grab and it turned out to be an RF64 file, however it was evident that our initial interpretation of the format specification was mistaken.
From the RF64 specification:
“For all three 32-bit fields of the RIFF/WAVE format the following rule applies:
If the 32-bit value in the field is not “-1” (= FFFFFFFF hex) then this 32-bit value is used. If the 32-bit value in the field is “-1” the 64-bit value in the ‘ds64’ chunk is used instead.”
So our expectation of the bytes 0xFFFFFFFF from position 0x04 is incorrect and we need to allow 4 wildcard bytes instead to represent the variable nature of this field. I’ll also add this in to September’s PRONOM signature release.
Dave Heelas, A Transforming Archives Trainee from Hull History Centre, inspired by Jenny Mitcham’s post, contributed a signature for the Final Draft script writing file format, .fdr. Dave also wrote about his experience of creating his first signature.
Dave had some sample files from internal collections and was having difficulty sourcing more, but had also observed some common byte sequences and had suggested an initial signature.

From Dave: “I believe I have identified the correct byte sequence. In the examples I have it always starts with the block ‘FD FD FD FD 00’ then three variable bytes and then the hex for ‘2 Final Draft, Inc. Final Draft’. Giving us this sequence:
‘FD FD FD FD 00 ?? ?? ?? FF FF FF FF FF FF FF FF
00 00 00 32 00 00 00 11 46 69 6E 61 6C 20 44 72
61 66 74 2C 20 49 6E 63 2E 00 00 00 0B 46 69 6E
61 6C 20 44 72 61 66 74 00 00 00 00 00 01 00 00’”
Dave proposed using the first four bytes “0xFDFDFDFD” as the signature; however I felt that this might not be strong enough, and that the signature might benefit from including the string ‘Final Draft, Inc.’
Dave then asked ‘Is there a limit for when creating the signature or is it better to simply make it as long as possible if it seems to be unique to the file type? Is there a cut-off point where you think it has gone on long enough?’
I replied that again, there’s no hard and fast rule, and ideally we’d be driven by what a formal format specification was telling us. In this case a single repeated byte ‘0xFD’ – even though the creators probably chose this byte as it fits the initials for Final Draft – doesn’t feel particularly strong in and of itself and there’s the potential for another format vendor to choose an identical sequence.
I helped find some further samples by searching Google for ‘”final draft” filetype:fdr’ and more through searching for the observed sequences ‘”ýýýý” “Final Draft, Inc”’ (ý being the extended ASCII character code for byte 0xFD) and these all showed almost the same pattern in Dave’s initial observation (the fifth byte 0x00 wasn’t always 0x00, and those four bytes at positions 0x04-07 probably represent some kind of size value), however the text string ‘Final Draft, Inc.’ wasn’t always in exactly the same position, so we settled on a final PRONOM signature of:
FDFDFDFD{12-64}46696E616C2044726166742C20496E63
The {12-64} part above says “we expect a gap between the first and second sequence of between 12 and 64 bytes.”
We have the chance to improve the signature over time, perhaps if a formal specification becomes available, or if we find .fdr files that challenge our current assumptions.
In all three examples I’ve discussed how file format specifications are the best guide to developing file format identification signatures. These can sometimes be easy to track down – a simple web search for “<XXXXX> file format specification”, where XXXXX is the name or extension of the file format is often enough. However since most file formats are proprietary, and many file format vendors feel there is a competitive advantage in not publishing their specifications, a search for official specifications can be fruitless. Other good sources for detailed file format information include custom parsers that render or process particular formats, or where individuals have attempted to reverse engineer proprietary formats.
In addition to the above examples, last week a representative from Docuteam in Switzerland contacted the PRONOM mailbox to tell us of a PDF/A-1 edge case where the PDF supertype is version 1.6 rather than 1.4. Andrea from Archives New Zealand pointed out some missing priority information for PDF/X via GitHub, and a contact from Bibliothèque cantonale et universitaire – Lausanne (also Switzerland) provided us with information to add the ‘Music Encoding Initiative’ file format to PRONOM via the PRONOM submission form.
I hope this post has helped to shine a light on some of the work that goes on behind the scenes here at PRONOM HQ (The National Archives, UK). There seems to be a concerted push toward community collaboration with file format research and signature development recently and we very much welcome it.

