
When we work with government records we tend to work on file formats. We think about documents in formats such as PDF, or DOCX (Word), or PPT (PowerPoint), or other exotic formats such as Serif PagePlus. We tend not to think as much about the web, for one, it can be argued that it is its own separate discipline, complementary, and somewhere between digital preservation, and archives more generally. Yet, as soon as we type a hyperlink into a Word document, what do we have? We have a link out to the web. It doesn’t magically make that document the world-wide-web, but we have given the document a new intrinsic characteristic, it relies on the web to aid with interpretation or understanding. When we look at that link, we will probably find something about it that will require preservation. How do record that information? How do we expose its existence? How do we preserve hyperlinks in documentary heritage?
Documents and authenticity
According to UNESCO, the authenticity of a record can be jeopardized by:
Threats to integrity. Changes to the content of the object itself also potentially damage authenticity. Most such changes stem from threats to the object at a data level.
A hyperlink is data. It is content, it can be evidential; , a missing link in a document makes us question what was there.
Intersection of the web and Documents
Web preservation is largely focused on crawling the known web. But what about the links that are otherwise locked in documents, e.g. PDF, DOCX, PPT, transferred or deposited to a collecting institution?
Studies that look at this includes:
- Burnhill et al. (2015) describe the extent of the problem.
- Zittrain et al. (2014) describe extent and previous studies for the Harvard Law Review.
- Jones et al. (2016) describe content drift in scholarly articles.
- Zhou et al. (2014) describe another study of reference rot in scholarly papers.
The studies each look at the extent of ‘link rot’ in scholarly publishing – largely PDF in each.
Jones et al. (2016) showed that:
- 81.5% is the total number of URI articles in their corpus that suffer from link rot or content drift.
- Only 21.8% that suffer link rot (67,071 out of 308,162) have representative snapshots (Mementos)
- 59.7% that suffer content drift (184,065 out of 308,162), also have representative Mementos)
So link rot and content drift is happening in some domains. And strategies are proposed for combating this in the long-term. Burnhill et al. (2015) summarize a few of those that have been discussed in the community:
- Using robust links during preparation of a paper.
- Archive links during submission to a publication system.
- Post-publishing with the user utilizing a Memento service, e.g. via the Time Travel API to retrieve links when they access an article.
Everything that has been has passed
This blog will not look at the first strategy here; using robust links in the preparation of a document. We set that aside as a potential future state for government where the infrastructure is correctly set up — imagine: “government hosted robust links for agencies”.
Instead we will look at strategies two and three and ask what can we do in the position of a receiving institution where records are years (potentially decades) old?
I want to suggest a workflow for the web-archiving of documentary heritage as follows:
- Extract,
- Audit,
- Report,
- Collect,
- Describe.
- (Optionally) Fix.
In more detail, each of these steps look as follows.
Extract
We use a utility to access the content of a record and extract all the links (we will propose a tool later).
Audit
The collecting institution should have a record, of the types of link in the collections that have been transferred or deposited.
- Types of link: HTTP, HTTPS, FTP, internet-based, or intranet-based e.g. link to an enterprise content management system; or link to a Wikipedia article etc.
- Status of the link: 2xx OK, 4xx Client Error, moved, gone, pay-walled, requires authentication, etc.
Report
This report is used internally, and is distributed to the agency (and depositor) of the state of things. In our developing line of work, evidence that needs to be done to improve processes in future.
Collect
Links that are alive still need collecting. As simple as saying to the Internet Archive or other service like Archive-It ‘save this’. For links that are gone, can we use a Memento (archived web snapshot) service to find a link to the original record? For ECMS links, can we still collect the original document as part of a transfer or split transfer?
Describe
You have at least three states of potentially evidential hyperlink in your record:
- Links that are OK (and now saved).
- Links that have gone but available as a Memento.
- Links that have disappeared entirely.
When a user accesses your catalog, I suggest we give them the courtesy of knowing what to expect whether a link a link has gone or not. We can use our catalog description to do this. We can look at it as a link out to another record; a mechanism to aid discovery; or it could be listed as information in a preservation status field.
(Optionally) Fix
It is entirely possible to take a (digital) scalpel to a record, lift out the broken link, and replace it with something robust – to fix it. This would result in a second preservation master. Whether or not we should? I will leave that up to a discussion.
HTTPreserve in this Workflow
I’ve created a suite of small utilities to help with this work. The three main components (out of a handful), are:
HTTPreserve: tikalinkextract
Built on the premise that we can use Apache Tika’s server mode to bulk extract text content from the files that Tika can handle. Tikalinkextract creates a CSV containing the filename it extracted a link from, and the link itself. It is an alternative to the proposed method in Zhou et al. (2014). Zhou et al. Use the tool pdftohtml to extract links from the XML the tool can produce. Tika, however, has support for a much wider range of file formats.
EDIT (2017): I have written an OPF blog post about this tool specifically.
HTTPreserve: HTTPreserve and HTTPreserve.info
HTTPreserve provides an API (application programming interface) for accessing existing web-archives, and optionally creating a new snapshot.
It is also a web service: http://httpreserve.info
The utility has just two endpoints:
- /httpreserve?url={url}&filename={filename.txt} – provides httpreserve stats about a link
- /save?url={url}&filename={filename.txt} – manages a save transaction with the internet archive and returns a httpreserve stat structure to the user
Give it a try!
http://httpreserve.info/httpreserve?url=https://staging.openpreservation.org/&filename=report_nameCURL:
curl –i –X GET http://httpreserve.info/httpreserve?url=https://staging.openpreservation.org/&filename="report_name"The structure is designed to aid reporting. It uses the filename (optional) as a way of tagging it, and it includes a Base64 encoded image snapshot of the website that can be used for detection of content drift.
Example output:
{
"FileName": "report_name",
"AnalysisVersionNumber": "0.0.15",
"AnalysisVersionText": "exponentialDK-httpreserve/0.0.15",
"SimpleRequestVersion": "httpreserve-simplerequest/0.0.4",
"Link": "https://staging.openpreservation.org/",
"Title": "home page - open preservation foundation",
"ContentType": "text/html; charset=UTF-8",
"ResponseCode": 200,
"ResponseText": "OK",
"SourceURL": "https://staging.openpreservation.org/",
"ScreenShot": "snapshots are not currently enabled",
"InternetArchiveLinkEarliest": "http://web.archive.org/web/20110902185220/http://staging.openpreservation.org/",
"InternetArchiveEarliestDate": "2011-09-02 18:52:20 +0000 UTC",
"InternetArchiveLinkLatest": "http://web.archive.org/web/20250207073912/https://staging.openpreservation.org/",
"InternetArchiveLatestDate": "2025-02-07 07:39:12 +0000 UTC",
"InternetArchiveSaveLink": "http://web.archive.org/save/https://staging.openpreservation.org/",
"InternetArchiveResponseCode": 302,
"InternetArchiveResponseText": "Found",
"RobustLinkEarliest": "<a href='http://web.archive.org/web/20110902185220/http://staging.openpreservation.org/' data-originalurl='https://staging.openpreservation.org/' data-versiondate='2011-09-02'>HTTPreserve Robust Link - simply replace this text!!</a>",
"RobustLinkLatest": "<a href='http://web.archive.org/web/20250207073912/https://staging.openpreservation.org/' data-originalurl='https://staging.openpreservation.org/' data-versiondate='2025-02-07'>HTTPreserve Robust Link - simply replace this text!!</a>",
"PWID": "urn:pwid:archive.org:2025-02-07T07:39:12Z:page:https://staging.openpreservation.org/",
"Archived": true,
"Error": false,
"ErrorMessage": "",
"StatsCreationTime": "1.995479418s"
}The command will work in CURL. You can also use CURL to gleam more information:
curl -s -i -X OPTIONS http://httpreserve.info | less And the tool is itself a Golang library, which is fully documented.
HTTPreserve: workbench
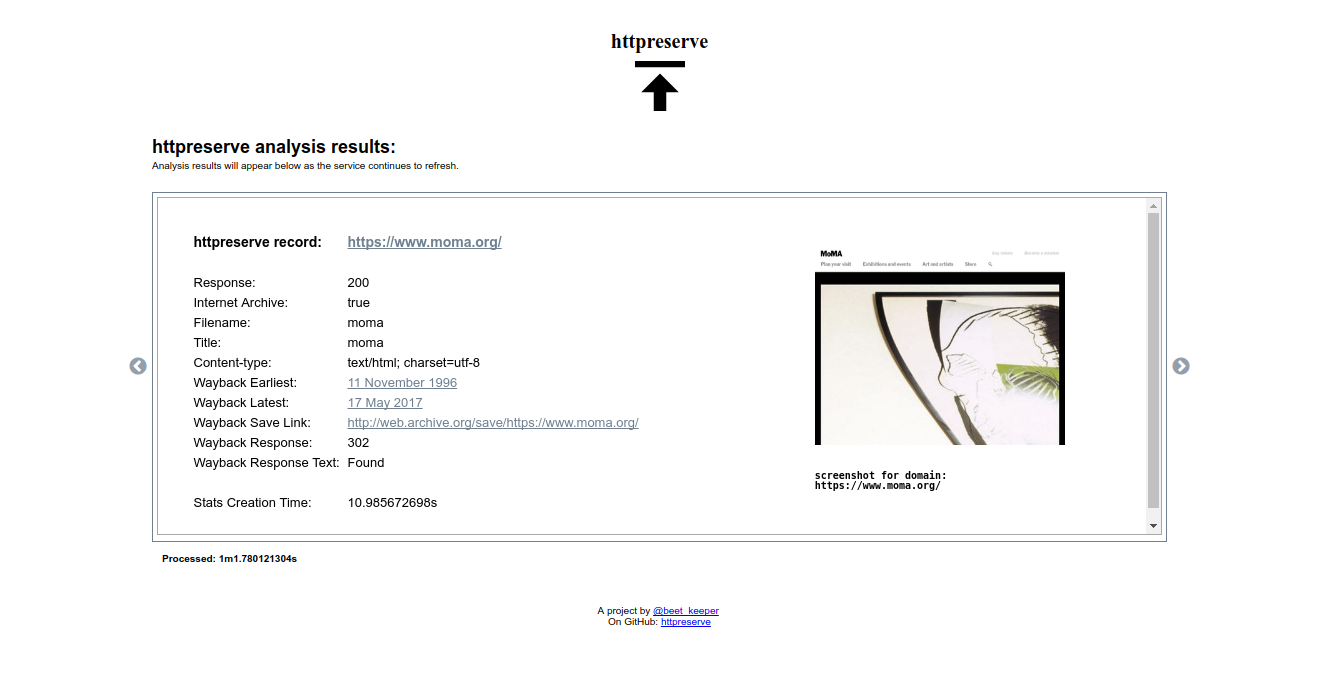
Workbench is a first attempt to wrap some of the bulk capability of HTTPreserve, and has a couple of modes; two of note.
The webapp (workbench) shown above is designed to give archivists full control over their process of auditing and ‘collecting’. I hope to add some tagging functionality to output in a report as well. Tags might be ‘content drifted’, ‘content gone’. These could all be part of an aggregate report.
There may also be effective automated processes which exist that I’d like to hear more about.
CSV output
Workbench can output information in a spreadsheet CSV (comma separated values) and that may be useful to recreate studies such as those in the introduction – to create consistent reporting for anyone researching link rot and content drift across domains. It’s also a more traditional way of recording information for our organization’s records.
JSON can be output with the same information.
EDIT (2019): I converted the web-ui to a command line interface (CLI) for ease of use.
What next?
Given this tooling, it’d be great to be able to explore link-rot in more detail. A couple of things are planned:
- Explore our collections at Archives New Zealand: we have approximately 6000 records to scan and audit for their hyperlink quality.
- Create of an ‘executive summary’ of our results that can be easily understood by those without deep knowledge of HTTP status codes and web-archiving principles.
- Explore memento: using other internet archives in this work will be beneficial to all, but how do we choose the best snapshot from a given Memento? Take for example these two for “http://bbc.co.uk” at the University of North Carolina (UNC) and the Internet Archive
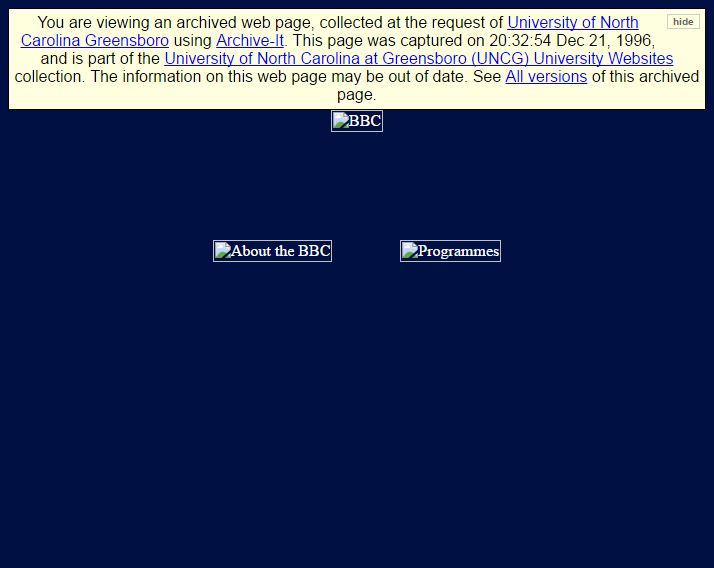

The UNC snapshot doesn’t have images where the Internet Archive one does – it is potentially a more complete record of this website circa 1996.
- We need to understand how to use these tools in an ingest workflow, i.e. as part of characterization. The basic functionality of HTTPreserve and http://httpreserve.info gives us a lot of flexibility to do that.
- We need to determine the extent to which these tools should be incorporated into archival workflows, e.g. collection strategies, and within archival description.
I want to hear from folk who are interested in this work, possibly testing it. I’m keen to hear feedback on the proposed methodology and it would be great to hear from people willing to test it. I also want to hear from folk with tools that might already do some, or all of this better.
If you’ve made it to the end of this post, you may also be interested in Nicola Laurent’s writing about the emotional impact of the 404 error.
This blog is in preparation for being at WADL2017 in Toronto where I’ll be presenting a poster and lightning talk on this work. I would love to hear more from y’all there.
EDIT (2025): Blog is modified to replace broken hyperlinks, update SEO and tagging, and to provide a much needed introduction to this work for context.
