
In a previous blog post I showed how we resurrected NL-menu, the first Dutch web index. It explains how we recovered the site’s data from an old CD-ROM, and how we subsequently created a local copy of the site by serving the CD-ROM’s contents on the Apache web server. This follow-up post covers the final step: crawling the resurrected site to a WARC file that can be ingested into our web archive.
Previous work
A 2016 report by Jeroen van Luin documents the web archiving workflows that are used by the National Archives of the Netherlands. Interestingly, it also covers the archiving of websites that are no longer online from local copies. Since this is similar to our NL-menu case, I took this as a starting point. The report mentions two general workflows for crawling from localhost:
Preparation: change machine system date, disable network connection
In most cases it will be desirable that the site snapshot will appear in the Wayback timeline around the year/date it was actually online. This can be achieved by setting the computer’s system date to that date. This has to be done before running the crawl. In the case of NL-menu I used the "last modified" time stamp of the files on the CD-ROM filesystem as an approximation. On a Linux-based system the following command will do the trick:
sudo date --set="2004-01-23 21:03:09.000"Also, to completely rule out anything from the "live" web leaking into the crawl, it may be prudent to disable the network connection at this point (both wired and wireless connections).
Heritrix
I started out with some limited tests with Heritrix 3, but this resulted in several problems. Most importantly, Heritrix appeared to ignore the hosts file on my machine (this file maps the domain www.nl-menu.nl to the localhost IP-adress). The effect of this was, that with the network disabled the crawl job would run indefinitely without ever downloading any data. After enabling the network, Heritrix would crawl the "live" site at www.nl-menu.nl instead of the locally resurrected version1. Because of this, I quickly gave up on Heritrix, and moved on to wget.
wget: first attempt
After some experimentation, the following set of wget options appeared to work reasonably well2:
wget --mirror \
--page-requisites \
--adjust-extension \
--warc-file="nl-menu" \
--warc-cdx \
--output-file="nl-menu.log" \
http://www.nl-menu.nl/The above command results in a 200 MB compressed WARC file, a mirror of the crawled directory tree, a CDX index file (not really nececessary, but useful for quality checks), and a log file.
Rendering the WARC
In order to test the rendering of the WARC locally, I installed pywb (which is part of the Webrecorder project). I then created a test archive using:
wb-manager init my-web-archiveand then added my newly created WARC using:
wb-manager add my-web-archive ~/NL-menu/warc-wget/nl-menu.warc.gzI then started the server with the command:
waybackAfter this the archive is available from http://localhost:8080/my-web-archive/. Below is a screenshot of one page:
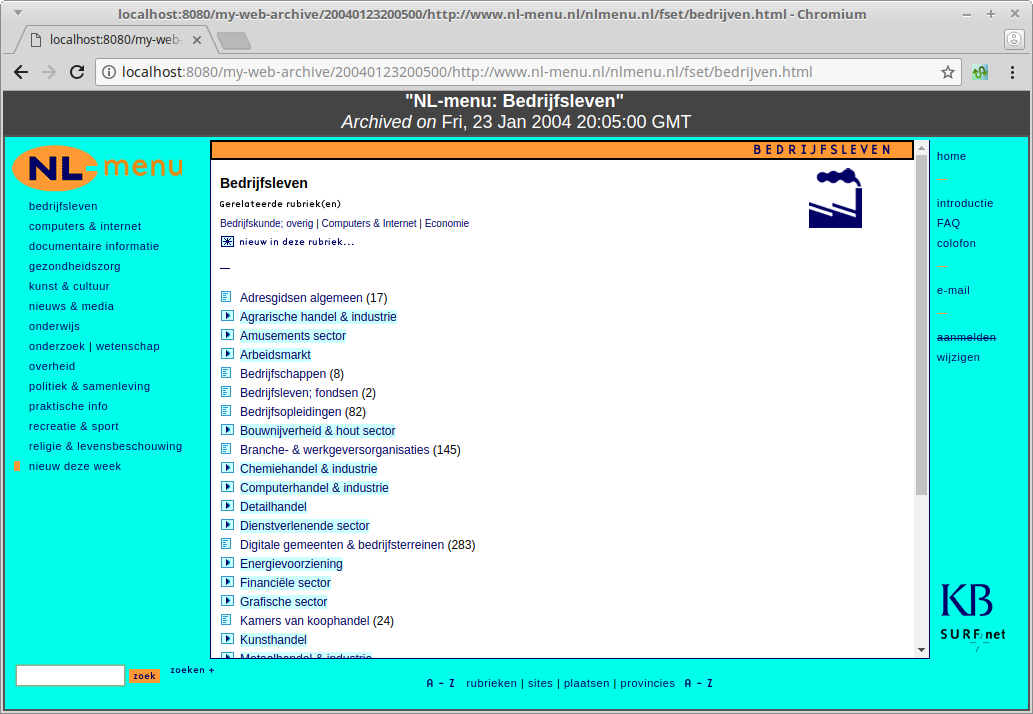
Note that the Archived date as shown by pywb corresponds to our modified system date (i.e. 23 january 2004).
Completeness checks
An analysis of the completeness of the wget capture3 revealed that over 660 files from the NL-menu source directory tree were missing in the crawl. Most (90%) of these were missing because they are simply not referenced (by way of a hyperlink) by any of the website resources that are crawled from the site root. Of the remaining 64 missing files, 51 are referenced through JavaScript variables (which are understandably not picked up by wget’s crawl mechanism). Other, less common reasons were:
- A file is only referenced through a value attribute of an input element.
- A file is only referenced through a src attribute of a frame element.
Thhis raises the obvious question: can we force wget to crawl all files in the source directory? Of course we can!
Wget: use –input-file switch with URL list
The solution here is to use wget‘s --input-file switch, which takes a list of URLs which are sequentially crawled. As a first step we need to create a directory listing of the source directory of the website, and then transform each file entry into a corresponding URL. I did this using the following command:
find /var/www/www.nl-menu.nl -type f \
| sed -e 's/\/var\/www\//http:\/\//g' > urls.txtI then ran wget4:
wget --page-requisites \
--warc-file="nl-menu" \
--warc-cdx \
--output-file="nl-menu.log" \
--input-file=urls.txtThis results in a WARC file that contains all files from the source directory. But it does introduce a different problem: when the WARC is accessed using pywb, it shows up as over 80 thousand individual captures (i.e. each file appears to be treated as an individual capture)! This makes rendering of the WARC near impossible (if only because loading the list of captures is extremely slow to begin with).
After getting in touch with pywb author Ilya Kreymer, Ilya pointed out that pywb‘s behaviour here is the combined effect of a bug in pywb and a peculiarity of the NL-menu directory tree: unlike most websites, it does not contain an index document (e.g. index.html) at the domain root level. Instead, the domain root contains 2 directories which hold the Dutch and English-language versions of the site, respectively:
/var/www/www.nl-menu.nl/
├── nlmenu.en
│ ├── index.html
│ ├── ...
│ ├── ...
│ └── ...
└── nlmenu.nl
├── index.html
├── ...
├── ...
└── ...The result of this is that the input URL list (which is derived from files in the directory tree) does not contain the site’s root URL (http://www.nl-menu.nl), which in turn ends up missing in the WARC. Ultimately this leads pywb to do a prefix query which in this case results in 80 thousand URLs!
Improved URL list
Ilya suggested to avoid this problem by explicitly adding the domain root to the URL list:
echo "http://www.nl-menu.nl/" > urls.txtIncidentally we also need to add entries for the root directories of the Dutch and English language sub-sites:
echo "http://www.nl-menu.nl/nlmenu.nl/" >> urls.txt
echo "http://www.nl-menu.nl/nlmenu.en/" >> urls.txtThen we can add the remaining files (and rewrite file paths as URLs) as before:
find /var/www/www.nl-menu.nl -type f \
| sed -e 's/\/var\/www\//http:\/\//g' > urls.txtFinally run wget:
wget --page-requisites \
--warc-file="nl-menu" \
--warc-cdx \
--output-file="nl-menu.log" \
--input-file=urls.txtThis results in a WARC that is complete and renders in pywb as well. On a side note, although rendering and navigating the site works well overall, there are still some small issues. For one thing, coming from the Dutch or English-language home page, clicking on the link to the site’s registration page results in a Url Not Found error, even though this page loads without problems coming from any other page on the site. I don’t really understand why this happens, although I suspect a combination of JavaScript and early-2000s frames madness may be to blame here.
Authenticity and provenance
My previous blog post contained the following observation on authenticity and provenance:
For one thing, we need to record metadata that makes it absolutely clear that our archival snapshot was taken from a locally reconstructed copy, rather than the original site.
So the more specific question is: does the WARC that we just created contain any metadata about the provenance of this snapshot? To find out, let’s use the warcdump tool that is part of the warctools toolkit:
warcdump nl-menu.warc.gz > nl-menu-dump.txtThis results in a (huge) text file with metadata about all archived resources inside the WARC. Here is an example of one (request) record:
archive record at nl-menu.warc.gz:75708014
Headers:
WARC-Type:request
WARC-Target-URI:<http://www.nl-menu.nl/nlmenu.en/index.html>
Content-Type:application/http;msgtype=request
WARC-Date:2004-01-23T20:04:54Z
WARC-Record-ID:<urn:uuid:4b05df6b-d408-4f2f-8efb-bbd38098cbdb>
WARC-IP-Address:127.0.0.1
WARC-Warcinfo-ID:<urn:uuid:7dacf508-ab81-4244-ae9c-ce04a1e18123>
WARC-Block-Digest:sha1:MJEIKQUIEOMARJPUEYXZFT4TTTUKX2IE
Content-Length:159
Content Headers:
Content-Type : application/http;msgtype=request
Content-Length : 159
Content:
GET /nlmenu\x2Een/index\x2Ehtml HTTP/1\x2E1\xD\xAUser\x2DAgent\x3A Wget/1\x2E19 \x28linux\x2Dgnu\x29\xD\xAAccept\x3A \x2A/\x2A\xD\xAAccept\x2DEncoding\x3A identity\xD\xAHost\x3A www\x2Enl\x2Dmenu\x2Enl\xD\xAConnection\x3A Keep\x2DAlive\xD\xA\xD\xA
...Note this line:
WARC-IP-Address:127.0.0.1The field WARC-IP-Address is defined in the WARC specification as:
The WARC-IP-Address is the numeric Internet address contacted to retrieve any included content. An IPv4 address shall be written as a “dotted quad”; an IPv6 address shall be written as specified in [RFC4291]. For a HTTP retrieval, this will be the IP address used at retrieval time corresponding to the hostname in the record’s target-Uri.
In this case, the value 127.0.0.1 (=localhost) unambiguously shows that this resource was crawled from a local copy, and not from the live web. So the required provenance metadata does indeed exist5
Conclusion
The above steps complete the recovery and archiving of the NL-menu website. In the coming months the KB will start some more "web archaeology" activities, and it will be interesting to see to what extent these wget "recipes" will work for other offline web content. In any case they may be a useful starting point.
Acknowledgements
Thanks are due to Ilya Kreymer, Raffaele Messuti and Andy Jackson for their helpful suggestions on wget and pywb, and René Voorburg for his suggestions on improving and quality-checking the crawl.
Additional resources
-
Jeroen van Luin, Experiences with web archiving in the Dutch National Archives. Report, National Archives of the Netherlands
-
Rough working notes on quality/completeness checks – unedited notes on some of the tests I did to assess the crawl quality (mostly in terms of completeness)
-
pywb, Core Python Web Archiving Toolkit for replay and recording of web archives
-
A site still exists at this domain, even though its contents are now largely unrelated to the original NL-menu↩
-
Compared with the examples in the NA documentation, this leaves out the -w (wait) switch (since we are crawling from a local machine it is safe to crawl at maximum speed), the -k (convert links) switch, and the -E (adjust extension) switch. It also adds the –warc-cdx command (which writes an index file) and the –output-file switch (which writes a log)↩
-
A detailed discussion of the methods that were used for this analysis is beyond the scope of this blog post; however some rough working notes are available here.↩
-
Note that I removed the
--mirroroption here, as it seems that this causes wget to do a recursive crawl for each single URL in the list. The result of this is that wget keeps crawling for hours without any (new) data being added to the crawl result.↩ -
How this particular type of provenance metadata is exposed to a user of the web archive is a different matter↩