
Introduction
Digital collections in the British Library include a variety of forms, such as books, journals, manuscripts, maps, music, photographs, newspapers and sound, but all are stored in the form of content and metadata structured around a METS file. We are moving these digital collections from our the existing repository system to a new repository system, Libsafe. One thing we noticed as part of this move was that our METS files have a lot of leading and trailing white spaces to improve human readability, and so we wondered whether we could save some space by simply removing the leading and trailing white spaces from the METS file and if so , how much storage space we could save.
Context
Metadata in the British Library consists of files such as METS files, ONIX and ALTO XML, and covers around 3% of the storage of our entire collection . Our METS metadata files are stored in the xml format which contains carriage return, line feed , tab and space charactersbar which although makes the files human readable, they adds extra unnecessary characters to the file and also occupies space in the storage. Fig 1 highlights inter-element carriage returns (CR) and tabs (T) that are typically used to pretty print the XML.

Fig 2 shows the XML file after removing the whitespaces such as carriage return and tab.

Methodology
We took a sample of 1000 METS XML files from our ebook collection and analysed for space saving. I developed a python script that initially downloaded all the sample METS XML files into a folder called original files. It then removed the white spaces from each METS xml file and saved them into a separate folder called reduced files folder. Next I calculated the size of each original METS file and reduced METS file and compared the sizes . Fig 3 shows the methodology
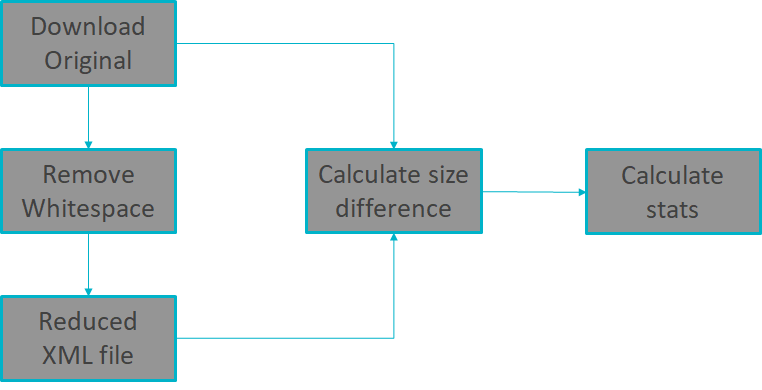
Fig3
Results & Analysis
Space saving
The initial size of the sample of 1000 ebook metadata xml files is 20.89 MB and after removing the leading and trailing white spaces from the xml files the total size is reduced to 16.51MB. The amount of space saved is close to 4.38MB which is approximately 21% of the entire sample. A simple stats run on the files shows, in table 1, that the average space saved is 4.38KB per file with a standard deviation of 0.411KB
| Total number of XML files | Initial size (for 1000 files) | Final size (for 1000 files) | Space saved (for 1000 files) | Average space saved per file | Percentage saved |
| 1000 | 20.89 MB | 16.51 MB | 4.38 MB | 4.38 KB ±0.411 KB (Std.Dev) | 20.95% |
Therefore considering the size of the entire collection of ebook metadata files which currently stands close to 12GB, the above procedure suggests an average saving of 2.52GB of space can be achieved for the ebook collection alone by removing the leading and trailing white spaces.
Human and Machine Readability
We did some further tests to ensure that the reduced size files could be read by both humans and machines. We tested upload to our new repository system and found that it could successfully process the reduced files into the new repository system, extracting out relevant metadata from them. Furthermore, the repository’s web front end was able to prettyprint the METS file for human readability.
Expanding on this idea, we found that the reduced METS files could be opened in a prettyprinted human readable form using a range of online tools, applications and plugins, such as xmlgrid.net, XML Notepad 2007, Altova XMLSpy, Geany’s Pretty-Printer plugin, Notepad++’s XML Tools plugin, Exchanger XML Editor, Stylus Studio, xmllint command line tool, as well as in popular web browsers: Chrome, Internet Explorer, Edge, and Firefox.
Conclusion
In this current work we considered just one collection(ebooks) for the purpose of analysis. The approach followed here saves a considerable amount of storage space. Our analysis suggests approximately 21% of the storage of each METS files is made up from newline and leading whitespaces. Removing this whitespace would allow us to better utilise our storage to preserve more digital collection items for the same storage cost. In addition to the increased storage capacity, it may also result in increased speed of ingestion and access. We are currently applying this whitespace removal technique to our other collections, to see if the same savings hold and to get more accurate space saving estimates.


