

Collateral use of Digital Preservation for other departments
What’s the opposite of collateral damage? Collateral use? That’s what our Digital Preservation workflows are for some other departments in our library. They put the digital content on their digital preservation platforms, for example the Open Access Repository EconStor, and we archive during the next night. As this is all automated, it literally happens during our sleep. Of course we do all the mandatory checking, including format check, validation checks and extraction of metadata. If a PDF (EconStor usually hosts PDF files) is broken, our tools notice that. We can give a feedback the next day and our workmates can ask the data producer for a replacement.
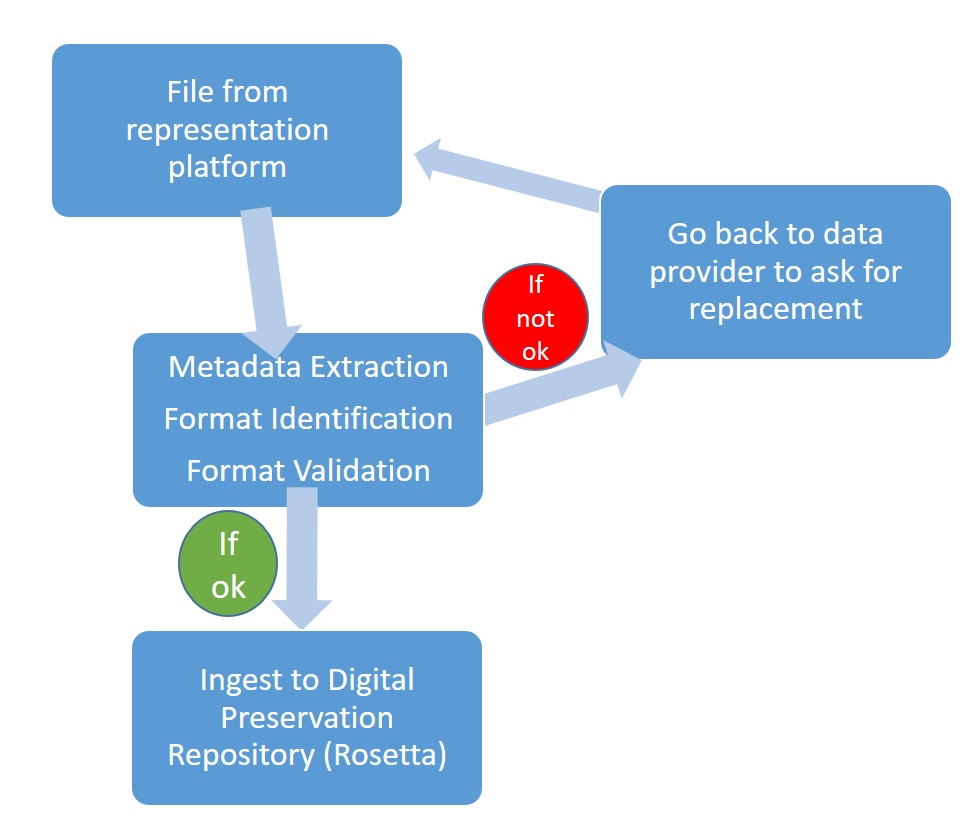
As this check is done directly after the acquisition, the data producer usually is easy to reach and a replacement is easily on the way. So much for EconStor.
What if it’s much slower?
But there are other platforms, other departments which acquire digital content and not everything is ingested the night after data acquisition.
I pick one example for this blogpost: The national and alliance licences. We are allowed to host and to ingest into the Digital Archive, but usually this goes very slowly. The colleagues from the responsible acquisition team get the content (usually PDF files) in large ZIP-Files.
It’s necessary to check for completeness and integrity, of course, which takes some time. The longterm-archiving is last in the object processing pipeline. There can be months, sometimes years, between acquisition and the ingest into the Archive. If corrupted objects are detected so late, it’s usually too late so ask for a replacement. The ZBW has been operating a Digital Archive since 2015 and experience has shown that the success rate has been very bad in the past, when asking for replacement more than a few weeks after acquisition of the data.
We needed a good post-acquisition workflow to check the data quality. Preferably fast and automatically, as staff time is always scarce.
The solution
We have established a workflow for now, as following:
Shortly after acquiring the content, the teammates unpack all the ZIPs and check for completeness.
Afterwards, all the PDF files go through a rough validation check, using ExifTool, Grep and PDFInfo. We have decided against JHOVE for two reasons:
- It’s much slower and we are usually dealing with more than 10,000 PDF files
- It’s much pickier and gives lots of false alarms and error messages we can ignore for now and fix later on (link to iPRES paper which examines this)
There are three possible outcomes:
- PDF has no error message: no action necessary
- PDF is encrypted: In this case, we contact the data provider and ask for a replacement with a decrypted PDF or for permission to crack the password protection. So far we have experienced good cooperation from the publishers in this case. The decryption will be the topic of another blogpost.
- Tool throws an Error for the examined PDF files
The third case is within the scope of this blogpost, because (as it is the case with most tools) not every error message has an impact on the ability of the PDF file to be archived.
Time needed for a bulk of 1000 PDF files
The runtime of the tools is pretty fast. The tool Grep only needs seconds. Therefore, it takes more time-consuming to change the settings of the script to the folder which has to be examined.
Depending on the size of the PDF files, ExifTool needs between one minute (if the PDF files have an average size of 1 MB) and ten minutes (if the PDF files have an average size of 32 MB). Of course, the manual examination (done by the acquisition team) which is necessary for some Errors (see next chapter) and the documentation need some time as well, especially when the workflow has only recently established and when the acquisition team runs into a new error message which has not been examined and documented yet.
Once the workflow has been established, including all needed scripts, by our experience, a bulk of 1000 PDF files needs between 30 and 60 minutes, if there are not too many Errors or unknown error messages. For the Digital Preservation Team, there is half an hour on top, if something has to be examined further, which was always necessary at the beginning. Once the workflows have been established, this is an exception, and this is why the staff time can be neglected.
Conclusion: Up to one hour for a 1000-PDF-Files folder
ExifTool error messages
There is a myriad of error messages, which we can ignore for know. This had to be tested when the workflow was first established, of course. We followed the steps as following:
- Collect all the PDF files for which ExifTool threw an Error, preferably with the same wording (at least very similar)
- check some of them manually and via Hex Editor (check if PDF can be opened, sight check)
- test a migration to PDF/A-2b via the pdfaPilot for all of them. If migration fails, check the error (sometimes the error is unrelated to the issue found by ExifTool, e. g. the failed migration is due to non-embedded fonts)
- Document all the findings transparently for all colleagues involved in the workflow
- decide how to proceed (see chapter “Conclusion and further work”)
After proceeding through these steps, it became obvious that some ExifTool error messages can be ignored, as the impact on the ability to be archived (and even migrated to PDF/A-2b) is negligible:
- Empty XMP
- Duplicate Info dictionary
- Bad AAPLKeywords reference
- Root Object not found at offset XXX
- Unsupported PNG Filter
- XMP format error (no closing tag for xxx)
- the PDF 2.0 specification is held hostage by the ISO
However, there were several error messages which had an impact on readability or the possible migration to PDF/A-2b:
PDF header is not at start of file
In case of this error message, there are more or less two options. In some cases, there is a free line above the PDF header, which is easy to fix by deletion of the line and usually has no impact on the readability – or migrationability (ability to migrate the file) of the file. But a further examination of the file is necessary, as some files which throw this kind of error only purport to be a PDF file, but instead are just copies of the messages an html page has shown instead of the actual PDF, like a 404-message or a request for a login. As these PDF files have not been downloaded properly, a re-acquisition is necessary and a fast contact to the data provider useful.

Junk data at the beginning of file

More junk data at the beginning of file

File is an HTML file
Bad length ICC-profile
This is an error which usually makes the migration to PDF/A-2b impossible. We have not yet found a tool which can fix the error. However, the data provider was not able to provide a PDF file with a better quality, either, so that’s something we will have to live with.
Error reading xref table (and other errors concerning the xref-table)
This has a bad impact on migrationability, but at least we have been able to fix some of the PDF files, depending on the error.
Conclusion and future work
We have decided to proceed like this:
PDF files with PDF header problems (or trailer problems, if such will occur) will be tested manually, and, if they turn out to be no PDF files or not completely downloaded, the data provider is asked for a replacement immediately.
All the errors concerning problems with the ICC profile or the xref tables are collected for further tests.
If a new error (new: not known to us yet) occurs more than ten times, the PDF files are collected and further testing will be performed.
The ingest of this content will be done over the course of the year 2022. While ingesting, testing with JHOVE and some metadata extraction tools will be done, so that further knowledge can be gathered. It’s highly likely that I will revisit this topic in another blogpost quite soon.
Does anybody out there performs quality tests on PDFs with ExifTool? What is your experience with it?


April 13, 2023 @ 9:47 pm CEST
Great blog post. Thank you! An update to the hostage situation: https://github.com/exiftool/exiftool/issues/199