
Abstract()
This blog discusses what we have available in our toolkit for contributing more signatures to PRONOM for the benefit of the digital preservation community. It also discusses the potential issues we need to work around in the short time we have between controlled PRONOM releases. The blog outlines an idea for a temporary, federated approach utilizing GitHub, Siegfried and Roy, and the droid-list Google Group for working with custom DROID signatures, inspired by conversations with colleagues at The National Library of Australia that might deal with those shortcomings.
Main()
It remains to be seen what alternate methods will appear for registering file formats and importantly, identifying them for the requirements of digital preservation, but until such times as Tessella’s Linked Data Registry, or the NSLA Digital Preservation Technical Registry broach the public domain and begin to be accepted and used by the wider public, The National Archives: PRONOM, and its sister tool DROID remain de-facto.
One of the issues that the other initiatives have been trying to solve is the centralized nature of PRONOM and a perceived difficulty in influencing the content of the registry.
Until we have a more federated approach, personal experience demonstrates to me that the PRONOM contribution model described here can work in the short-term. Some of the challenge seems to lay in the discovery of specifications, or sample files; another part of the challenge is creating signatures.
We have guidance and mechanisms to aid in creating signatures; I created a PRONOM Signature Development Utility tool here (hosted by The National Archives, UK), and mirrored here (my personal website), with code, open source here (PHP+HTML), which outputs a single traditional DROID signature file that can be uploaded to the tool to be used.
Matt Palmer, former colleague at The National Archives, UK has recently developed a Java tool which does a similar task, here; each may satisfy different users’ requirements or workflows.
For specifications, then Google Search has always been a good first stop.
Format examples are a little more difficult, but, most users approaching the task of format identification should have a fistful of samples in their possession. Permissive institutional approaches to sharing those samples and trusting the confidentiality of institutions such as The National Archives in looking into format signatures helps.
A sample email one could write might look like this:
Dear PRONOM,
Please find attached a set of sample files for testing, please note the following caveats:
- These are [record classification here] deposited under [relevant legal act here]
- The access classification put on these files by the depositor is [access classification here]
- However, they are not yet available to the public
- We are yet to ingest them into the digital [repository/archive/etc.]
- They are provided purely for research and testing purposes for identification of the error involved.
- They are provided for access, only by those helping to identify the error involved.
- Once the testing is complete we ask you to delete the files
- If further testing is required in future, these files should be available again through our [archival/library] catalogue, once fully accessioned
Regards,
Signature Developer
And beyond The National Archives’ skilled help, we can always find more samples for ourselves. We can approach the community on Twitter; we can use the Google Groups, droid-list, or PRONOM list.
A favorite of mine is an extension based search for samples on Google e.g.
Though it can be harder to track down more specific and more esoteric formats in this manner.
A technique shown to me recently by Andy Jackson of the UK Web Archive is to use magic numbers to search for samples stored in their collection:
Find Serif PagePlus in the UKWA
This example, though an ever-so-slightly long-winded query string simply boils search of the UK Web Archive down to files with the OLE2 magic number 0xd0cf11e and extension .ppp which should help me to discover Serif PagePlus files for testing. Positives, or false positives all have their benefits when we’re testing the accuracy of any signature we’re developing.
Please note: This is very much a prototype service on offer from the UK Web Archive and it may go down at any point.
As mentioned in the introduction to this blog – alternate approaches seem to look to solve a problem with a centralized approach to maintaining a registry for format identification. Perhaps we do need a federated approach to a registry; but as a stopgap to that, a tool like Roy, and his partner tool Siegfried, created by Richard Lehane of State Records NSW, along with GitHub may help us to build a model providing a temporary federated approach to the distribution of file format signatures.
A distributed approach to publishing our (the community’s) own custom signatures may be as close an approach as we can get to a decentralized format registry model right now. Users and institutions with a GitHub can store their signatures on there, perhaps listing them on the droid-list on Google Groups. They can then be accessed by all users of Siegfried, and concatenated using Roy into a single signature file, or sets of signature file as appropriate.
Siegfried provides part of the provenance reporting showing how it reached a match on an object:
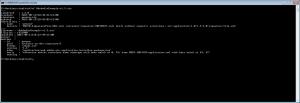
C:\Working\siegfried>sf AdobeAirExample-v1.5.air
---
siegfried : 1.2.0
scandate : 2015-08-11T18:56:23+12:00
signature : pronom.sig
created : 2015-08-11T18:56:21+12:00
identifiers :
- name : 'pronom'
details : 'DROID_SignatureFile_V82.xml; container-signature-20150327.xml; built without reports; extensions: air-application-1.0-1.5-2.0-signature-file.xml'
---
filename : 'AdobeAirExample-v1.5.air'
filesize : 1921900
modified : 2015-08-11T18:27:44+12:00
errors :
matches :
- id : pronom
puid : archives-nz-dev-signature/2
format : 'adobe.air'
version : '1.5'
mime : 'application/vnd.adobe.air-application-installer-package+zip'
basis : 'extension match; container name mimetype with byte match at 0, 59; name META-INF/AIR/application.xml with byte match at 69, 47'
warning :
The extension described here is to add a set of identification methods for the Adobe Air format type. The provenance we are interested in is that we’ve used the extension signature file air-application-1.0-1.5-2.0-signature-file.xml’ on top of the two standard DROID signature files.
N.B. As a result of writing this blog, Siegfried has already been updated to include the full set of extension files used in the details field and this blog will be updated as appropriate when I can build and test the tool.
The command for extending a signature file in Roy is:
roy build -noreports -extend air-application-1.0-1.5-2.0-signature-file.xml -extendc air-application-container-1.0-1.5-2.0-signature-20150623.xml
With more information available on the tool’s wiki
Both -extend and -extendc accept a list of comma separated values and so it is possible for me to extend this infinitely given a number of different custom signature files being made available to me.
Imagine if the identifiers list began to look a little something like this?
identifiers :
- name : 'pronom'
details : 'DROID_SignatureFile_V82.xml; container-signature-20150327.xml; built without reports; extensions: archives-nz-air-application-1.0-1.5-2.0-signature-file.xml, archivematica-forensic-disk-formats.xml, avpreserve-audiovisual-formats.xml, open-preserve-pdf-identifiers.xml, hatii-research-data-formats.xml'
And so forth.
DROID too could perhaps be improved to accept multiple custom signature files to be used concurrently with the primary DROID signature file, and including an extra ‘provenance’ column in the output CSV.
A workaround to using custom signature files is to use DROID’s command line CSV output:
droid -Nr “c:\working\air-files” -Ns air-application-1.0-1.5-2.0-signature-file.xml -Nc air-application-container-1.0-1.5-2.0-signature-20150623.xml
Though a more extensible and user-friendly solution from DROID would also benefit the community.
Before we can start making full use of Siegfried, and then maybe DROID, and before we can see the appearance of a suitable mechanism for a federated approach to signature distribution we need to start publishing our signatures files.
Archivematica for example uses custom FIDO signatures
And I’ve published a few as well, e.g. Adobe Air, Microsoft Word Template File
Though up until now, I fell into the trap of listing them on Google Groups only.
The next step-change will be to have these listed centrally and described appropriately using good style guidelines, especially the PUID, for example, adopting Archivematica style:
PUID: archivematica-fmt/2
And in the filename examples above, I might also include the correct institution, e.g.
Filename: archives-nz-air-application-1.0-1.5-2.0-signature-file.xml
From there they can be selected, downloaded, remixed and compiled using the Roy tool (N.B. potential for a web service?) and we, the community, can begin make use of a host of different identifications using DROID signature syntax that might otherwise remain in digital filing cabinets until such a time when a more appropriate registry appears lightening the burden of testing, and provenance on The National Archives, UK.
The comments that Mark Pearson of The National Library of Australia made that resonated with me were something that I know a large number of the digital preservation community already take advantage of: GitHub already provides a great infrastructure for distribution and Git itself a tool proven in the Linux community for distributed projects; as a version control system it can provide much of the provenance information we need, though some of this may also need to be accounted for in how we use custom Signature files.
Can it work as a temporary federated approach?
I think so.
My custom files though not many, and sample layout are here: https://github.com/exponential-decay/droid-signature-files
Where are yours?

September 30, 2015 @ 4:03 am CEST
Thanks Ross, I’d forgot about this proposal!
… anyway…
I’d be inclined just to have “superiorTo” and “subordinateTo” relations here & keep them functional: i.e. to just be about supporting identification of file formats by letting the identification engine know how to prioritise in scenarios of multiple matches.
You need to have both superior and subordinate relations so that Archivist X can define his extensions independently of Archivist Y and both can assert superior or subordinate relations against each other’s extensions. You could of course have standalone format definitions without any relations.
I’d be inclined to focus such a schema on the narrow task of describing a means to identify file formats & leave richer description (i.e. documenting all the different types of relations formats can have to each other, plus all the other descriptive info we’d like to have) to something else.
September 30, 2015 @ 2:13 am CEST
I realized I haven’t replied to this Richard. I think the syntax looks great. It combines the container sequences and byte sequences well. It brings the information from the first page of the PRONOM report which is otherwise obfuscated, about format relationships – this plays a big part in format identification as we know.
Do you envision always having a superiorTo relationship between formats? That is, is it purely a functional definition of a relationship or do we want to create a semantic connection between formats?
It’s nice, and I could see a simple schema being created to support it.
August 14, 2015 @ 9:02 am CEST
Very interesting post thanks Ross!
One question it raises for me is, what is the best syntax for encoding signature extensions? Given that PRONOM and DROID are already two different syntaxes, not to mention the separate container syntax, it may not hurt to diverge, particularly if we can make these files easier for users to create themselves.
The archivematica FIDO extensions in your post are a good example of a more accessible and readable way of expressing format signatures.
On twitter, Andy Jackson notes that he uses Tika syntax for extensions because he can encode relations between formats.
It seems like the ideal syntax would:
– be clean and readable
– allow you to encode both byte and container signatures
– allow you to express relations between formats
No tool supports it, but how about something like this:
https://gist.github.com/richardlehane/6e406eb5d6601ed8e726