
With the arrival of the new law for the legal deposit of the digital material, the library is receiving always more documents in PDF format. Those kind of document were already been provided by other partners who have performed a previous digitization. So we end up with a bunch of PDFs, some of which have been produced directly by digital means, and the others been the result of the concatenation of images generated by a scanning process. In the latter case, a hidden text layer, produced by an OCR tool, may also be present.
When it comes to preserve these artefacts, we generally need to sort the 2 kinds of PDF in order to process them differently. In particular, the treatment of the text layer is very different between them. In the case of digitally-born document, the text is error-free, while in the case of OCR, the accuracy of the engine dictates the quality of the result.
The question then is how to differentiate them knowing that both respect the PDF specifications.
The Human way
For a human, distinguishing one or the other case is quite straight forward. Just choose a random page and zoom it to the maximum level.
For a scanned page, you will get a blurry image as soon at the resolution rate has been excedeed.
On the contrary, for a native PDF, the graphics, vector-based, will remain smooth at any zoom level. The text in particular remains perfectly drawn.
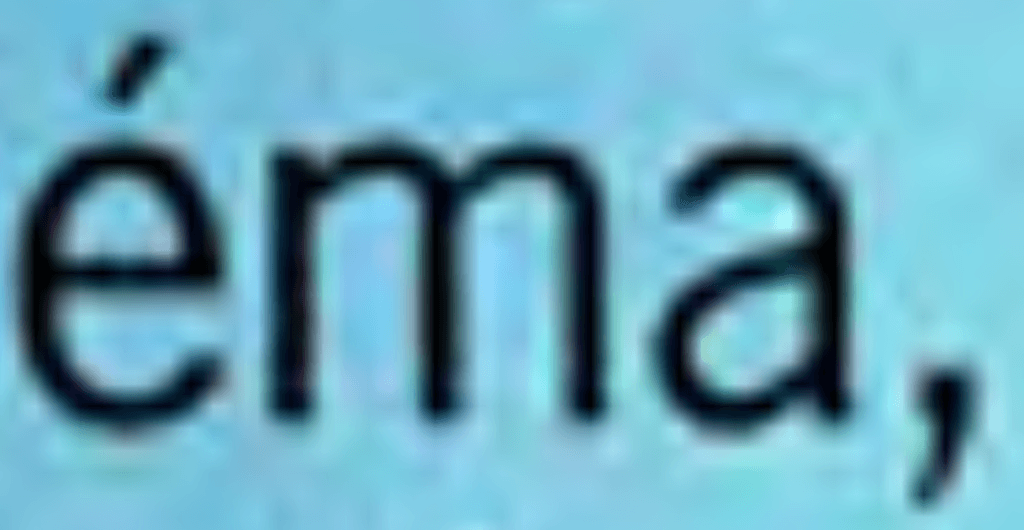
Zoom of a scanned PDF at 2400% 
Zoom of a native PDF at 2400%
Previous propositions
A naive approach is to use the metadata giving the tool that have created the PDF. However, this seems unreliable and error-prone.
A more comprehensive approach, that is described in stackoverflow, is to copy the PDF while stripping all the contained text. Then the two copies are transformed into a series of images. If the two series are equal, the conclusion is that the PDF originates from a scan. This approach seems perfect but it’s quite computationaly intensive and time consuming.
Heuristic-based proposal
The approach that we have implemented is made of an succession of heuristics. The goal is to have a reliable method which remains easy to compute.
Step One: Compare Numbers
The first step is to calculate the number of pages and the number of images of the PDF file. If these numbers do not match, it’s a native PDF. However, it is not because we have the same number of pages as images that we have a scanned PDF: the trivial counter-example is a single page with a logo…
Step Two: Compare Boxes
We then select a few pages at random (we arbitrarily choose 10). For each page, we retrieve the MediaBox of the page. The MediaBox is, as defined in the PDF specifications, a mandatory field that represents “a rectangle, expressed in default user space units [72 dpi], that shall define the boundaries of the physical medium on which the page shall be displayed or printed”.

We also get the dimension of the image. The tricky part to make it non-computation intensive is to retrieve this information from the technical metadata associated to the image and not by decompressing the entire image. The Width and Height of a image are extracted from the dictionnary associated with the objects of a page of type XObject and of subtype Image.
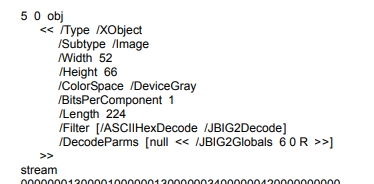
Having this information, we can assert that the dimension of the image is higher than the dimension of the page. And by a calculation, we can deduce the resolution in dpi of the potential scan.
We then collect these calculated resolutions and compare them. If most of them (we put the thresold at half of them) are equal, then we decide that the PDF is indeed a scan product and we can even provide the value of the resolution used during the scanning process.
Robustness of the method
The advantage of this method is that we are resilient to two possibilities :
- some pages of a native PDF came from a scan: this is often the case for cover or advertising pages. However, since they are the minority, the PDF file won’t pass the test
- some pages of a scanned PDF are computer generated: for example, our digital library, Gallica, adds a “how-to” page at the beggining of the PDF. Once again, since they are the minority, the PDF is recognized has originating from a scan.
Implementation
This method has been implemented in Java using the Apache PDFBox library . It can be found on the scannedPdf Github project.
Various experiments based on documents received or produced show that the heuristics choosen work and the time of processing is equivalent to a classic analysis.
The screenshot below shows the use of the method integrated in our tool Frontin, which is used to sort, identify and characterize digital collections.
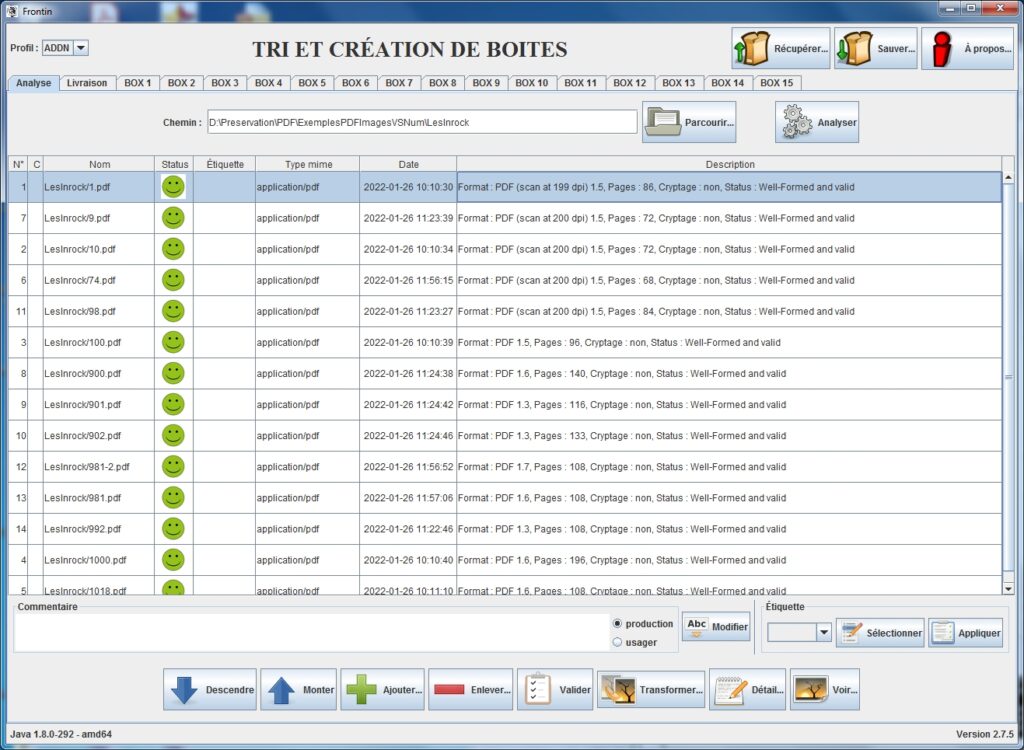
This use case highlights the fact that the first issues of the periodical were simple paper scans whereas the later ones were digitally generated.


