
We’ve all been using tools like JHOVE for years – yet we still fall short in sharing how we trouble-shoot validation errors and what they mean. In this blog post I want to showcase one of many possible root causes for PDF-hul-38, aka “Invalid object definition”. Instead of focusing on the JHOVE error message per se, I want to use the actual document as a starting point – the corpus delicti is called “Paper_35.pdf”. It’s an 8-page long engineering paper which is part of a conference proceedings publication. Unfortunately I cannot openly share the problematic PDF – but please reach out if you’d like to do some further analysis or have ideas about other steps that can be taken.
In the following sections, I’ll briefly describe “the symtoms” of the broken PDF, as presented to us through rendering software and validation tools. I’ll then dissect the different validation results and present an additional method before drawing a short conclusion and giving an outlook to potential further work.
The goal of the blog post is to share how errors like this one can be analyzed further and to give some context to the JHOVE error messages we’ve all come to love and fear. I also want to show how error messages can be linked to rendering behavior of a PDF document.
The symptoms
There are typically two different processes via which we detect faulty PDFs – visual analysis, aka “rendering”, and (automated) tool-supported file format anaysis, typically either “validation” or “technical metadata extraction”. Both have their weaknesses and benefits, but that’s for another time to discuss.
Since one of the questions we want to answer is how validation errors impact a PDF’s rendering bevavior, we’ll take a brief look at the PDF using both processes – rendering and validation.
Rendering behavior
Some validation errors more or less hit you in the face when you render a file, others are harder to detect or may not even have an impact on the rendering behavior per se. (Spoiler alert – this PDF throws two errors in JHOVE validation, one that hits you in the face and one that doesn’t have a real impact).
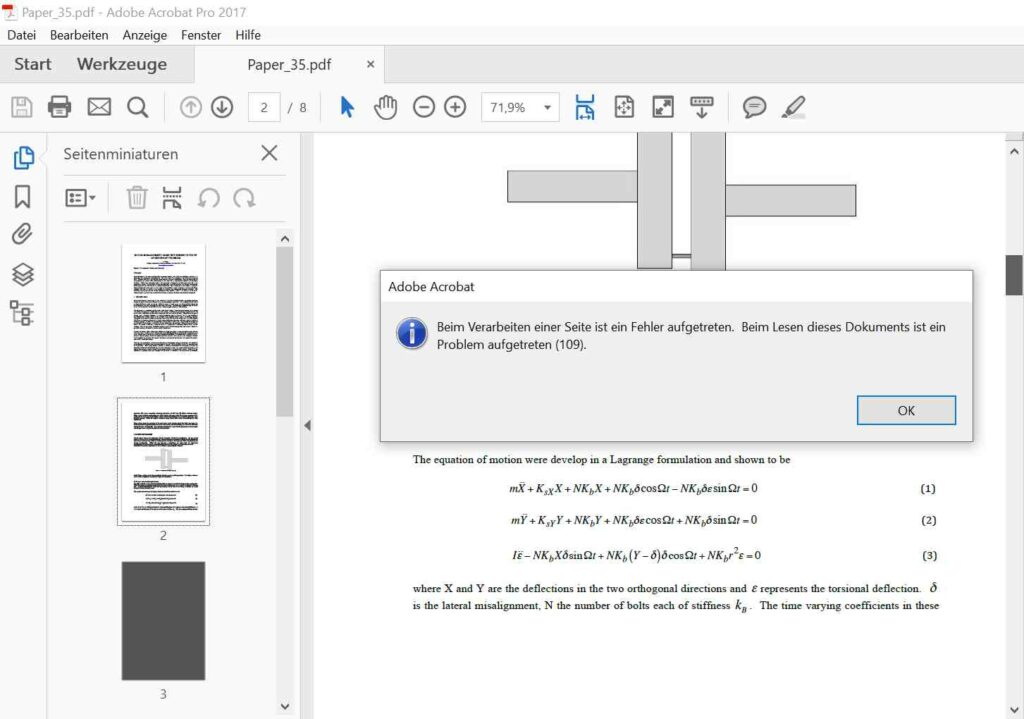
Opening the file in Adobe Acrobat (I used Adobe Acrobat Pro 2017). Was fine at first sight, but when scrolling through PDF towards page 3, an error occurs: “The document could not be saved. There was a problem reading this document (109).” Error 109 doesn’t bode well in Adobe Acrobat land – it essentially means that the file is corrupt. The rendering behavior can be seen in the screenshot – the file comes up as blank (see thumbnail view on the left, the error is on page 3, the main viewing window still shows page 2 in the background).
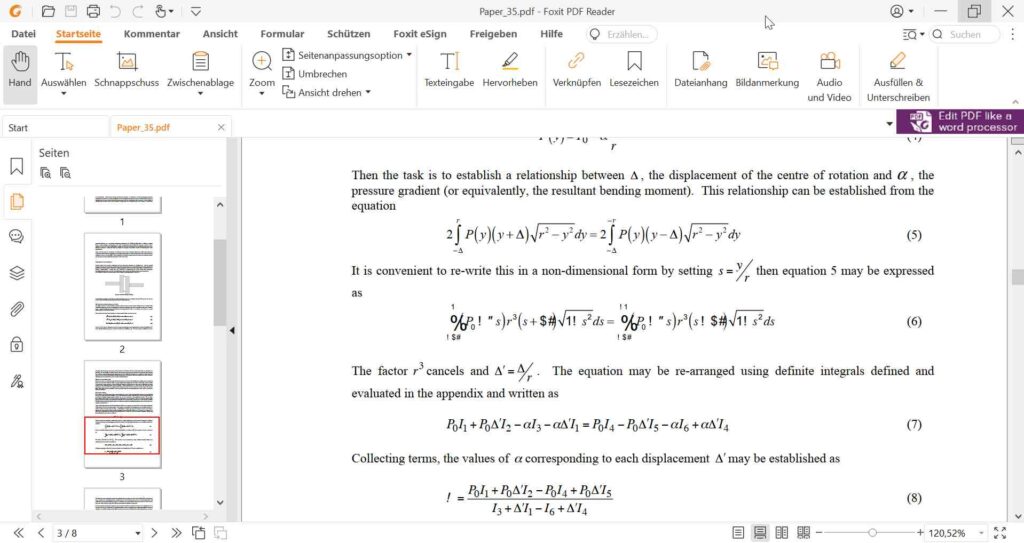
However, Adobe Acrobat is just one of many PDF viewers available and not all viewers behave the same way when encountering errors. When rendering the same PDF with Foxit PDF Reader (I used v12.0.1.12430), page 3 mysteriously appears without an error message at all!
So was fixing the problem as easy as using another viewing software? Not quite! While I’m not really good at math, even I can spot that something doesn’t seem right with formula 6. The characters “%”, “#”, “$” don’t seem to fit – and I would bet that the “1” and “!” above and below the “%” don’t belong there either.
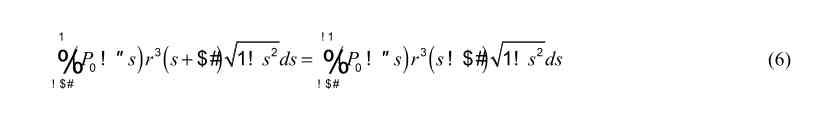
Another viewer I typically try is Ghostscript. Amongst rendering software, Ghostscript is the wise old program that hasn’t changed all that much in the past 30 years. It doesn’t have much to say about a lot of newer features, but it can give you helpful hints about basic things that are wrong. In Ghostscript (I use Ghostscript 10.0.0 for Windows (64 bit)), the rendered result looks the same as it did with Foxit, however, the prompt gives you some helpful pointers in form of 32 error messages regarding missing fonts on page 3:
- Loading font TT63 (or substitute) from %rom%Resource/Font/NimbusSans-Regular (occurance: 11 times)
- Loading font TT63 (or substitute) from %rom%Resource/Font/NimbusSans-Regular (occurance: 20 times)
- Loading font TT86 (or substitute) from %rom%Resource/Font/NimbusSans-Regular (occurance: 1 time)
This confirms our suspicion that something has gone terribly wrong with fonts.
Validation behavior
In digital preservation workflows, we typically become aware of dodgy PDF files via validation errors. On the top my PDF-validator-go-to-list are JHOVE, pdcpu (with validation mode strict) and qpdf (with the –check –verbose option).
| Tool | Output |
|---|---|
| JHOVE 1.26.1 (2022-07-14) with Module: PDF-hul 1.12.3 | Not well-formed PDF-HUL-87 = File header gives version as 1.3, but catalog dictionary gives version as 1.4 PDF-HUL-38 = Invalid object definition Offset 285259 |
| pdfcpu v0.3.13 dev | deferenceObject: problem dereferencing object 91: pdfcu: ParseObjectAttributes: can’t find “obj” |
| qpdf v9.1.1 | PDF Version: 1.3 File is not encrypted File is not linearized WARNING: Paper_35.pdf (object 18 0): object has offset 0 WARNING: Paper_35.pdf (object 22 0): object has offset 0 WARNING: Paper_35.pdf (object 25 0): object has offset 0 WARNING: Paper_35.pdf (object 28 0): object has offset 0 WARNING: Paper_35.pdf (object 31 0): object has offset 0 WARNING: Paper_35.pdf (object 34 0): object has offset 0 WARNING: Paper_35.pdf (object 37 0): object has offset 0 WARNING: Paper_35.pdf (object 40 0): object has offset 0 WARNING: Paper_35.pdf (object 42 0): object has offset 0 WARNING: Paper_35.pdf (object 44 0): object has offset 0 WARNING: Paper_35.pdf (object 49 0): object has offset 0 WARNING: Paper_35.pdf (object 51 0): object has offset 0 WARNING: Paper_35.pdf (object 53 0): object has offset 0 WARNING: Paper_35.pdf (object 69 0): object has offset 0 WARNING: Paper_35.pdf (object 75 0): object has offset 0 WARNING: Paper_35.pdf (object 77 0): object has offset 0 WARNING: Paper_35.pdf (object 80 0): object has offset 0 WARNING: Paper_35.pdf (object 82 0): object has offset 0 WARNING: Paper_35.pdf (object 87 0): object has offset 0 WARNING: Paper_35.pdf: file is damaged WARNING: Paper_35.pdf (object 91 0, offset 288300): expected n n obj WARNING: Paper_35.pdf: Attempting to reconstruct cross-reference table WARNING: Paper_35.pdf: object 91 0 not found in file after regenerating cross reference table WARNING: Paper_35.pdf (object 245 0, offset 278718): /Length key in stream dictionary is not an integer WARNING: Paper_35.pdf (object 245 0, offset 278783): attempting to recover stream length WARNING: Paper_35.pdf (object 245 0, offset 278783): recovered stream length: 4639 WARNING: Paper_35.pdf (object 256 0, offset 288288): unknown token while reading object; treating as string WARNING: Paper_35.pdf (object 256 0, offset 288300): expected endobj |
Dissecting the error messages
As we can see in the table above, the three different validators came back with a variety of errors. Let’s dissect them by their respective validation tool.
JHOVE Error message PDF-HUL-87
PDF-HUL-87 tells us that the “File header gives version as 1.3, but catalog dictionary gives version as 1.4”. In the section about rendering behavior I mentioned that one of the JHOVE errors doesn’t really have an impact on how the file is displayed – this is that error.
But what is this about two versions? The main location where a PDF tells us its version is in the header – the PDF magic byte/signature being %PDF-x.y where x is the major and y the minor version. The PDF 1.4 specification introduced a second place – a version entry in the document’s catalog dictionary. The rationale for this change lies in incremental updates, a method via which PDFs can be edited / changed and the internal strucutre can carry a history of updates. If present, the version entry in the catalog dictionary overrides the entry in the header. While this has an interesting implication on our current file format identification processes for PDF, the topic of incremental updates is an extensive topic I don’t want to expand further on, here …. because: Paper_35.pdf doesn’t have incremental updates. Yup, you heard that right – two different version entries, but no reason for them being there. That’s PDF for ya!
A couple of years ago there was a discussion around JHOVE messages being separated into ERRORs and WARNINGs – if this ever comes into fruitition, PDF-HUL-87 would be on my candidate list for “WARNING”, as the deviating version entries are more a feature than a bug.
JHOVE Error message PDF-HUL-38
PDF-HUL-38 “Invalid object definition” is one of the JHOVE errors I tend to take very seriously. Objects are the core building blocks of a PDF document and if one can’t be parsed correctly, there’s a good chance we might be in trouble. In addition to the error message, JHOVE reports an offset which we can use with a HexEditor to pinpoint the object that’s causing problems.
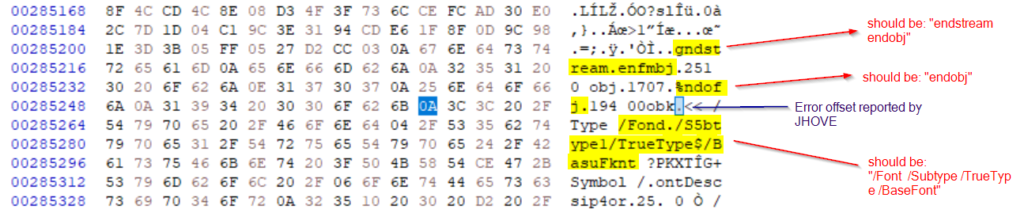
That being said, JHOVE offsets are typically to be taken with a grain of salt. It’s very beneficial to take a look at what happens before as well as after the reported offset. If we would just look from the offset onwards, we might arrive at the assumption that the PDF contains exactly 1 erronous object which is a Font dictionary. This would of course fit with what we saw in the rendering tests – but is that all that’s wrong? If we take a closer look at the HexEditor output, we can see that there is a serious case of gibberish going on before and and after the offset. Right at the offset what should have been “obj” came out as “obk”, making the object unusable. But even before the offset we can recognize keywords that have been mangled, like “enfmbj” that should be “endobj”.
But which objects are affected by the problem? It surely can’t be all if the pages in general can still be rendered. Unfortunatly, JHOVE cannot help us in finding out more about the problem but the tool told us that something is wrong with Paper_35.pdf. Very wrong.
pdfcpu Error message
pdfcpu doesn’t point us to an offset but indicates that there is a problem with one specific object – “deferenceObject: problem dereferencing object 91: pdfcu: ParseObjectAttributes: can’t find ‘obj’“. In other words: obj 91 is called from the document, but cannot be found. Through simple text search or a pdf structure viewer of your choice, we can easily find the place that references object 91:
68 0 obj
<</ProcSet[/PDF /Text] /ColorSpace << /Cs5 79 0 R /Cs3 20 0 R /Cs 1 7 0 R /Font << /TT74 102 0 R /TT88 116 0 R /TT76 104 0 R /TT86 114 0 R /TT55 83 0 R /TT60 88 0 R /TT51 78 0 R /TT46 73 0 R /TT82 110 0 R /TT56 84 0 R /TT84 112 0 R /TT62 90 0 R /TT71 99 0 R /TT49 76 0 R /TT45 72 0 R /TT47 74 0 R /TT68 96 0 R /TT72 100 0 R /TT73 101 0 R /TT58 86 0 R /TT66 94 0 R /TT91 119 0 R /TT57 85 0 R /TT1 8 0 R /TT67 95 0 R /TT2 9 0 R /TT43 70 0 R /TT69 97 0 R /TT61 89 0 R /TT89 117 0 R /TT64 92 0 R /TT75 103 0 R /TT78 106 0 R /TT53 81 0 R /TT63 91 0 R /TT44 71 0 R /TT80 108 0 R /TT87 115 0 R >> >>
endobj
When we search for “91 0 obj” in the PDF, we cannot find it – so it’s exactly like pdfcpu said: an object is referenced, but can’t be found. Similar to JHOVE, pdfcpu points us to exactly one problematic object. Also, we can see that obj 91 should include Font information (this becomes clear by the fact that it’s in a /ProcSet ditionary). The ProcSet description is for resources used in Page 3 – the page with the problematic formula, so the pdfcpu output seems to match what we saw during our rendering tests. But again, is this all? Is just one font problematic?
qpdf Warning messages
Amongst the validators tried, qpdf is the most talkative one. It gives warnings for 22 different objects. For 19 of those, qpdf just warns that the “object has offset 0”. The offsets of PDFs are stored in the document’s xref-table. Running qpdf with the option –show-xref gives you the content of the xref-table in a human readable form and helps us understand the warning. The xref table has entries for the 19 objects, but contains “0” as the offset where they can be found. In other words, it’s a really complicated way of saying “18 is an object number but it is currently not used in the document”.
The warnings for objects 91, 245 and 256 are more interesting. As is the general observation, that the file is damaged 😀 We already established in the analysis of the pdfcpu output that object 91 is problematic because it can’t be found and qpdf comes to the same result with “object 91 0 not found in file after regenerating cross reference table”. However, qpdf is nice and additionally gives us the expected offset (288300) for object 91, which we can again inspect with the HexEditor or other tools.
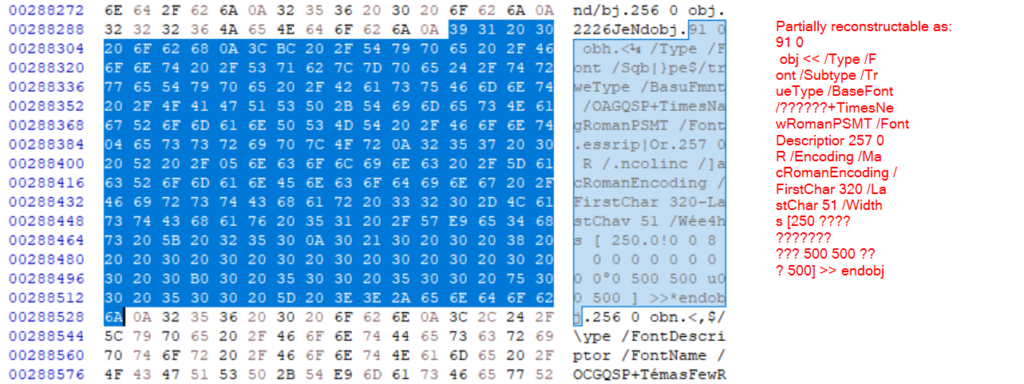
In the image above we can see that obj 91 has encountered a fate similiar to the objects around the JHOVE offset – the bytes are rather fuzzed and the output has partially turned into gibberish. We can try to reconstruct some of the content – for fixed dictionary keys like /BaseFont (was in mangled form: /BasuFmnt) this is fairly straightforward, but it’s more complicated for variables.
Following obj 91 we can see obj 256 (a Font Descriptor object) with also a mangled form, which explains the qpdf errors for that object. Object 246 is a stream object, which looks good in the beginning, but the end of it is mangled. The object also can’t be reconstructed via decompression, which makes salviging it fairly impossible, I believe.
Error message summary
As can be seen by the detailed discussions for each validator, each tool has it’s strengths and weaknesses – nothing new here. But what is the knowledge we’ve gathered about the PDF file by combining all three outputs?
I would summarize it as:
– something is wrong with obj 91, which we’ve established to be the font shortlisted at /TT63
– objects 245 and 256 are corrupt, potentially more
Structure analysis as a means of validation
We’ve talked about testing the rendering behavior and (automated) file format validation to find out that something is systematically broken within a PDF. There’s a third method, which is somewhat in between those two processes – manual or tool-supported structure analysis. True, it’s what drives validators, but validators are only as good as the code behind them and some structure analysis tools are really good at what they do.
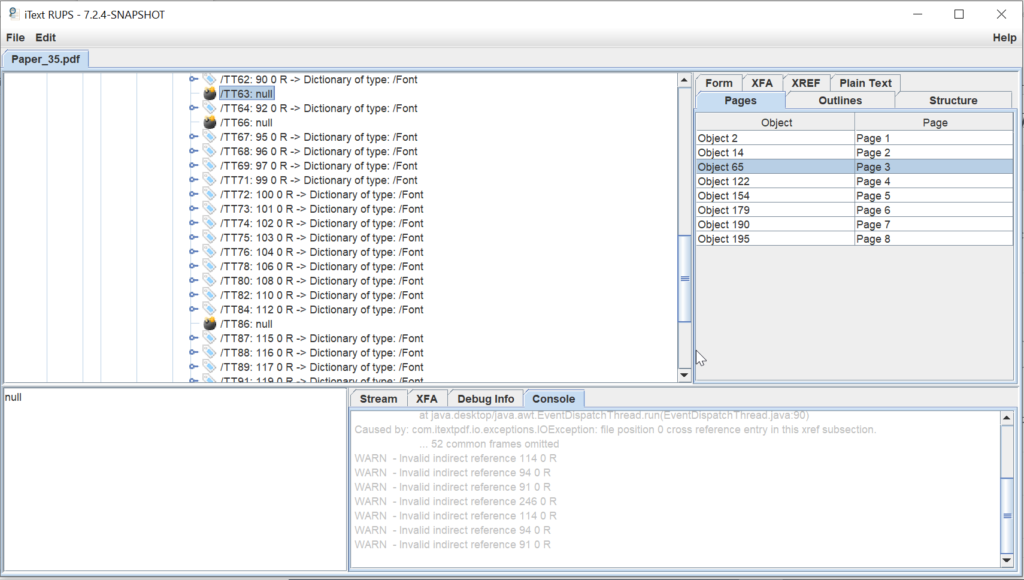
One of the tools I use frequently is iText RUPS a “Diagnostic Tool for Reading and Updating PDF Syntax & Debugging PDF code”. As opposed to the validators, iText RUPS allows us to specifically look for problems per Page by clicking ourselves through the resources. The screenshot below shows what the tools tells us about the problematic page 3:
- 3 font objects are missing (/TT63, /TT66 and /TT86)
- invalid object references for 91 (font dictionary for /TT63), 94 (font dictionary for /TT66), 114 (/font dictionary for /TT86) and 246 (stream object)
Comparing Rendering analysis, validation and strucutre analysis results
It’s safe to say that we’ve etablished that the PDF is more or less broken. But what method did the best job at helping us figure out what is wrong with it?
The rendering test is fairly straightforward – that is, if you know what you’re looking at (Designated Community and Knowledge base, anyone?). I personally cannot say for certain which characters of the formula are wrong and which aren’t.
The validators did a better job as far us plainly telling us that “something is wrong”. Again, interpretation of the validation results requires some expertise knowledge (digitial preservationists as a designated community in their own rights!). A key take-away for readers should be that JHOVE PDF-HUL 38 errors should not to be ignored. Personally, I think qpdf did the best job in regards to error detail as it pointed us to several broken objects. On the other hand, I appreciate the simplicity of both the JHOVE and pdfcpu error output, even though they do fall a bit short in regards to analysis.
The structure viewer iText RUPS did the best job in linking problematic objects to resources called by the actual problematic page 3 of the document. RUPS and Ghostscript were also the only tools that picked up on 3 broken font objects and not just on the one /TT63 object.
And now what? Can we fix it?
The ultimate question is now, of course, has all this analysis helped us in a way that we can now fix the problem? The short answer is: I don’t know (yet?). I’ve managed to extract and uncompress the stream object that “draws” (in pdf terms) the glyphs for the formula onto the page. Alas, actually figuring out the character then requires further information about the font descriptors, which are, as described above, partially mangled. Part of me says that it’s a waste to completly discard an object that is only partially not renderable. The other part of me knows that reconstructing the information is not possible through an automatic way and would require some more digging. Which is fun, of course, and it’s the sort of work I thrive on … but who has the time these days?
And if you made it this far: for fun and giggles I’ve converted the file with pdftk which, non-chalantly and without a warning, created a new well-formed and valid PDF version with the wrong forumla. May that be a warning for all those normalization friends out there 😉
What I neglected to mention in the introduction to this blog post is that the PDF came off of an USB stick. The imaging / file vacuuming of the USB sticks is done directly by our acquisition teams. Over the course of the past 5 years I’ve come across a few cases of such “mangled” PDFs, which leads me to suspect that the USBs might be broken or something is wrong with the imaging process. But that’s for another blog post to explore – the point of this one was to showcase JHOVE error message analysis.


April 5, 2023 @ 12:31 pm CEST
Thanks!
Typically it’s an indicator for a buch of fuzzing going on from then onwards. Fixing the obk into obj is fairly straight-forward, of course. If you then re-validate the file the next error pops up. There will be places which you can’t correct because there is no way to guess what the original text was supposed to be – esp. in the case of streams. In the end there’s typically no way to fix this :-/
April 3, 2023 @ 12:59 pm CEST
Nice BlogPost Micky!
You have found a few errors like obk instead of obj.
What happens, if you correct them by hand as far as you know?