
A little while ago I introduced a new file format identification tool, siegfried, on this blog. Since then, I’ve been refining the tool, with a goal of a 1.0 release early next year (probably around March). I hope you don’t mind the occasional update about my progress on this blog.
One of my goals with siegfried is to make a tool that has decent performance characteristics but that, in its default mode, faithfully applies PRONOM signatures. What this means in practice is that, if siegfried needs to scan an entire PDF file to determine whether a PDF/A marker is present it will do so, even if this slows identification. This is how I like to do format identification (favouring comprehensiveness and accuracy over speed) but I’m aware that other use cases warrant different tradeoffs.
For example:
- an audio visual archive might favour accuracy and speed over comprehensiveness, and exclude non-AV formats from their search
- a web service might favour speed over both comprehensiveness and accuracy, and limit the number of bytes scanned, remove end-of-file sequences, and remove container signatures (which require seeking around the contents of files, so don’t work well with streams)
- an archive faced with a plethora of obscure formats might need a more comprehensive signature set than is offered by PRONOM and might extend their signatures with custom ones (which they’ve also contributed to PRONOM of course too!).
Both DROID and FIDO allow users to tune the matching process to satisfy these, and other, use cases. For example, users of DROID can control the number bytes scanned. Users of FIDO can also limit buffers as well as apply a number of other customisations including adding custom signatures, excluding signatures, excluding extension matching, etc.
Signature customisation
The latest version of siegfried includes a number of signature customisation options, such as:
-bof (set a maximum distance from the beginning of file for byte matches)
-eof (set a maximum distance from the end of file for byte matches)
-noeof (trim end of file sequences from signatures)
-nocontainer (exclude container signatures)
-nopriority (ignore signature priority rules, forcing a full scan of all files)
-limit (limit the signature set to a comma-separated list of signatures)
-exclude (exclude a comma-separated list of signatures from the signature set)
-extend (extend the signature set with custom signatures)
These options aren’t in the sf tool but are in a companion tool, roy. This is the tool that builds siegfried signature files. For example, the command:
roy build -name custom -bof 5000 -eof 1000 custom.gob
builds a custom signature file with maximum beginning of file and end of file offsets. When used with the sf tool, the output looks like this:
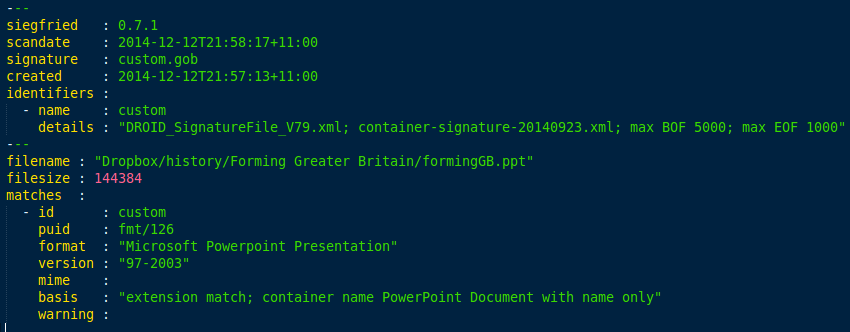
The benefit of hardcoding customisations in this way is that the signature file becomes a fixed record of those decisions. This makes it easier to track the basis of identifications, apply customisations consistently, and share customisations.
Multiple identifiers
One of siegfried’s other new features is its support for multiple identifiers. This means that a number of distinct sets of signatures can be co-located within a single signature file. When the sf tool is invoked with a signature file containing multiple identifiers, it will report matches for each of those identifiers. Because of the concurrent algorithms used by siegfried, having additional identifiers will not have a significant impact on matching speed.
The main reason for supporting multiple identifiers is to prepare siegfried to support additional signature formats (such as those used by the file tool). But this is a long way off (and not a version 1 feature!). In the meantime, you can do interesting things with multiple identifiers just using PRONOM signatures.
Multiple identifiers are useful if you are considering applying any of the signature customisations described above. For example, if you are considering setting a maximum beginning of file offset, then you could create a test signature file with a number of different offsets and then run that against a sample of files to see how different offsets affect results.
Multiple identifiers are also useful for tracking changes to PRONOM signatures over time. These commands:
roy build -name latest history.gob
roy add -name v10 -droid DROID_SignatureFile_V10.xml -noreports -nocontainer history.gob
roy add -name v35 -droid DROID_SignatureFile_V35.xml -noreports -nocontainer history.gob
create a signature file that has the most recent DROID signatures (version 79) as well as two older versions (versions 10 and 35). The -noreports and -nocontainer flags are necessary because I’m building directly from the DROID xml file here (not from XML reports from the PRONOM database) and don’t have matching old container files for those versions.
When matched against a file, the output looks like this:
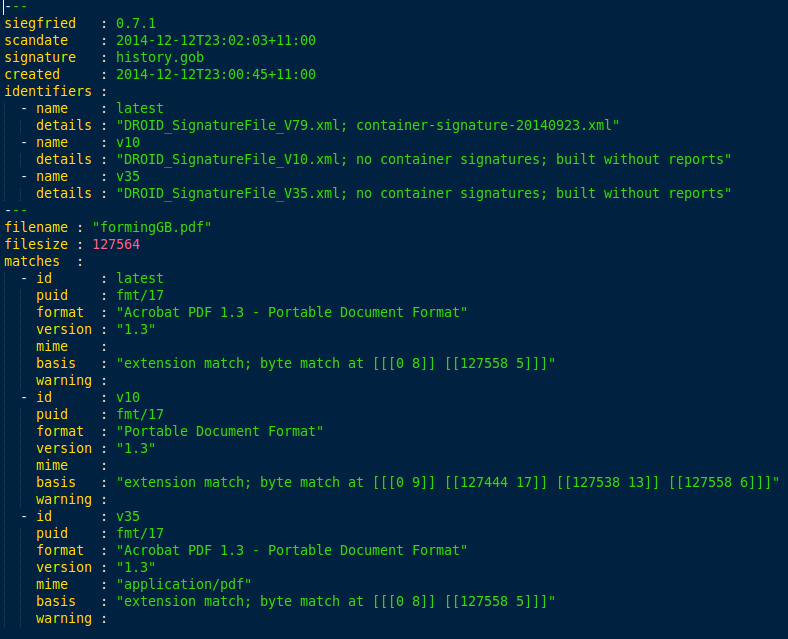
All three versions of DROID correctly identify the file as fmt/17 but they differ on basis – in the different offsets reported we can clearly see how that signature has changed over time.
There’s lots more you can do with roy’s signature customisation and multiple identifiers. For a full description of the options, please have a look at this page on the siegfried wiki.
