What’s in a Namespace? The Marriage of DROID and Siegfried Analysis…
With the release of the latest Siegfried there was added motivation for me to provide an analysis output for the format identification tool. With ‘double the magic’ there was a lot more for us to explore as analysts, and fingers crossed this release (a refactor) of my SQLite based analysis tool will help with that exploration.
Previous related blog links describe more of the purpose of this work, and how it can be used to create a rogues and heroes gallery for digital preservation triage.
The latest Siegfried release incorporates an additional identifier called MIME-Info specified by Freedesktop.org. This provides a whole new layer of capability on top of that provided by PRONOM. The benefits outlined by Richard:
- Speed
- Text Identification
- XML Identification
Richard talks in terms of format coverage and it is my hope that on some of our existing collections we will see gaps in format identification plugged by taking advantage of these features.
How does the SQLite Analysis Engine help?
The tool loads all of Siegfried’s results into a database and runs a set of queries against that database, outputting the results as a collection overview.

Along with more detailed output such as results per identifier:

In reality there has always been a lot to explore with Siegfried. One of the features I hope will be accentuated with this report style output is the rationale for Siegfried matching a file against a particular format identifier, examples of which are shown in the image below:
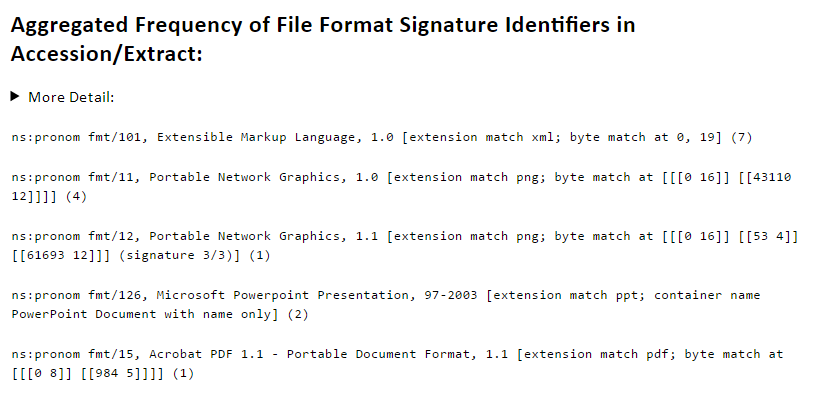
There are a number of reasons we might look at this as a format signature developer including identifying the thresholds within signatures that aren’t matching files that we believe should match, or discovering the wide variability of different signatures.
The queries used are all in the following class: https://github.com/exponential-decay/droid-sqlite-analysis/blob/master/libs/AnalysisQueriesClass.py
If there are other queries that you can think of to better explore these datasets, then please submit your ideas to the GitHub issues log.
What’s in a namespace?
Richard’s ingenuity in creating Siegfried was utilising namespaces. A namespace is a mechanism for making unique an element or name that might be found inside another class, and so for example, if the term ‘identifier’ can be found in two sets: PRONOM and Freedesktop.org, we can still differentiate between the two.
PRONOM:id : fmt/196
Freedesktop.org:id : 'application/x-adobe-indesign'
I have adopted this concept in the database structures used in this code. The namespace, like in Siegfried, allows for limitless combinations of identifiers and results. The challenge in creating overview statistics utilising namespaces is in identifying the canonical result for any one particular file identification.
I output sets of aggregate results alongside specific namespace results. Aggregated results order the output, first by namespace, and then, in order, the following:
- Positive Standard AND Container Signatures
- Positive XML Identifiers
- Positive Text Identifiers
- Positive Filename Identifiers
- Filename Extension Based Identifiers
This is one of the things I will need to test with your help in this release and the next few following that.
This is all good and well, but it’s all in Siegfried anyway?
Siegfried is now outputting more than double the data than it was before. This is my first attempt at managing that and making it immediately useful to all levels of user – there is also myriad data to mine within that.
Siegfried results are augmented by the faceting provided by an overview report; we can benefit from easy to parse summary statistics; and we’ve other features such as the pairing of Cooper Hewitt’s Unicode Library with analysis of collection filenames:
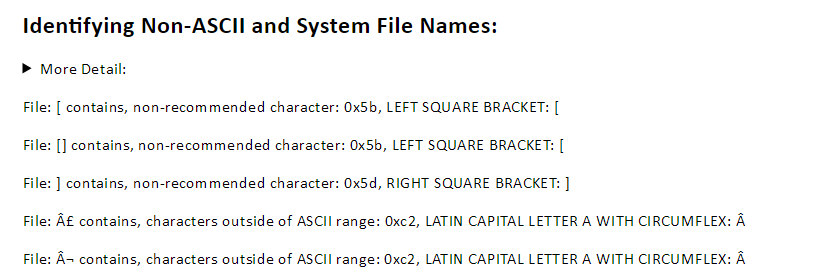
A Siegfried report, like a DROID CSV is a wonderful thing in its own right. I expect users to consult the analysis, but always refer back to the source when more detailed information is required. The two should work symbiotically with one another.
The nice thing about this collection overview is that it can provide a first stop to understanding a collection outside of a digital preservation system. We use it at Archives New Zealand for two reasons:
- It can help us understand a collection that hasn’t been officially transferred – and may never be transferred and as such is unsuitable for our digital preservation system.
- It can help make up for gaps in the digital preservation system such as an ineffective mechanism for dealing with issues during ingest. As such, helping us to understand what pre-conditioning may be required.
Tomorrow…
In tomorrow’s blog I will detail a handful of other features I think might be useful, including the potential to internationalize the tool.
The purpose of this first, very brief summary was just to let the world know that the tool is now there for users to take a look at and explore and to hopefully put it through its paces.
The release can be found here: https://github.com/exponential-decay/droid-siegfried-sqlite-analysis-engine/releases/tag/0.6.4-BETA
The issues log can be found here: https://github.com/exponential-decay/droid-sqlite-analysis/issues
Please do let me know what you think and please don’t keep bugs or issues to yourself.
[EDIT 2016-09-30] Link to release updated to most recent.